1. Pour réaliser une régression logistique, cliquez sur Analyse, Régression, Logistique binaire.
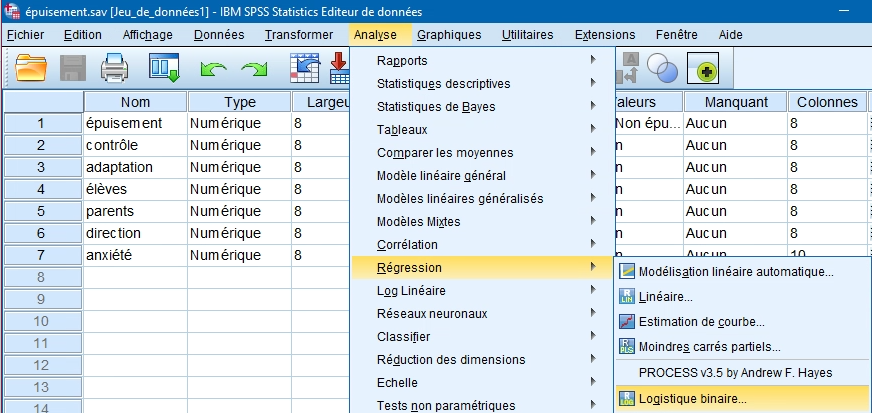
2. Dans la première boite de dialogue, insérez la variable dépendante dichotomique dans la boîte Dépendant et les variables prédictrices dans la boîte Covariables.
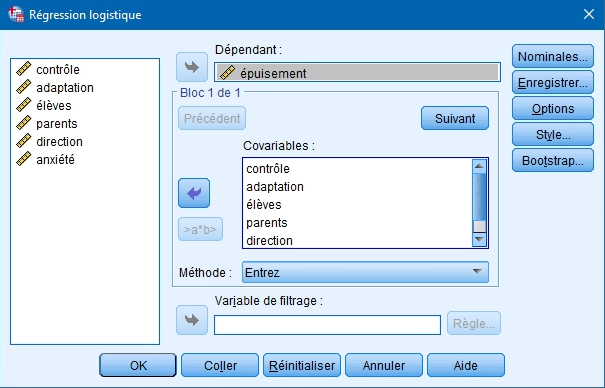
3. Si vous désirez insérer un terme d’interaction entre deux prédicteurs, sélectionnez les deux variables dans la boite de gauche et cliquez sur la flèche.
4. Choisissez ensuite la méthode de régression :
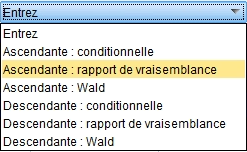
5. Pour réaliser l’analyse, cliquez sur OK.
Le bouton NOMINALES
Ce bouton permet d’indiquer à SPSS quelles variables soumises sont catégorielles dichotomiques. Il faut simplement les insérer dans la boite Covariables catégorielles.
Le contraste par défaut est Indicateur. Il s’agit de la technique de base pour catégoriser une variable catégorielle à plusieurs groupes en plusieurs variables n’ayant que les valeurs 0 et en 1 (variables dummy). Il s’agit simplement, pour une variable à 4 groupes (niveau de scolarité : primaire, secondaire, collégial et universitaire), de créer 3 variables, une pour les 3 premiers niveaux de scolarité. Par exemple, pour la variable primaire, ceux ayant le primaire comme plus haut niveau de scolarité auront la valeur 1 et les trois autres groupes, la valeur 0. Puisque les gens ayant un diplôme universitaire auront la valeur 0 dans les 3 variables, ils constitueront le groupe de référence à partir duquel les 3 autres seront comparés. Il est toutefois possible d’opter pour les autres types de contrastes en les sélectionnant dans le menu déroulant.
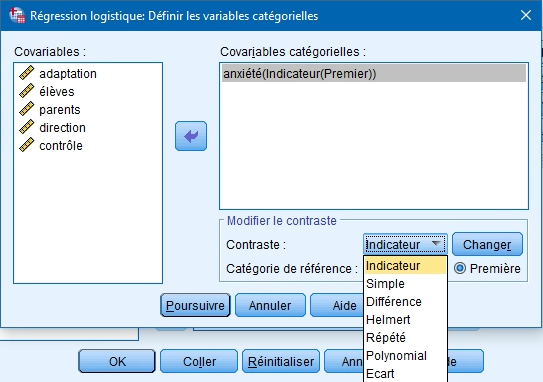
Le contraste indicateur est donc à recommander. Vous pouvez choisir la première ou la dernière catégorie comme modalité de référence. Si vous prenez la première (soit dans notre cas 0, non anxieux), n’oubliez pas de cliquer sur le bouton CHANGER.
Le bouton ENREGISTRER
Comme pour plusieurs types d’analyse, il est possible d’enregistrer en tant que nouvelles variables certaines informations d’intérêt, telles que les résiduels standardisés, les prévisions probabilités (valeurs P(Y) prédites à partir de l’équation) et les prévisions groupe d’affectation (prédiction du groupe dans lequel les individus seront inclus en fonction du modèle).
Il est également possible d’obtenir les autres formes de résidus et les statistiques d’influence présentées dans la régression simple. Le résidu logit est calculé à partir des coefficients logit.
Ces nouvelles variables serviront essentiellement à examiner la qualité d’ajustement du modèle.
Le bouton OPTIONS
Le dernier bouton comprend les options pour réaliser l’analyse ainsi que les les tableaux qui peuvent s’afficher dans les résultats. Il faut conserver les options par défaut.
- Probabilité pas à pas : comprend les points de coupure pour la sélection des variables dans les méthodes progressives. Idéalement, on maintient le critère à 0,05 pour l’ajout des variables et à 0,10 pour le retrait.
- Maximum des itérations (20) : représente le nombre d’essais maximal que SPSS utilisera pour identifier le meilleur modèle possible à partir des variables disponibles. À moins d’avoir un modèle excessivement complexe, ça ne devrait pas prendre plus de 20 essais.
- Inclure le terme constant dans le modèle : l’équation comprend le coefficient b0, ce qui favorise un modèle mieux ajusté aux données.
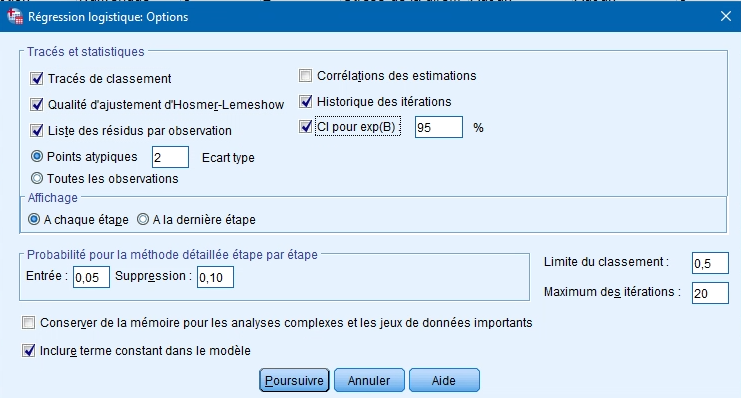
Les autres options disponbiles peuvent aussi être pertinentes.
- Tracés de classement : histogramme illustrant les valeurs prédites et observées. Il permet de juger l’ajustement du modèle.
- Qualité de l’ajustement de Hosmer-Lemeshow : test évaluant s’il y a une différence significative entre les valeurs observées et les valeurs prédites. Évidemment, on préfère que ce test soit non significatif.
- Liste des résidus par observation : soit pour les valeurs extrêmes (situées à plus de 2 écarts-types, il est toutefois possible de changer le critère), soit pour toutes les observations. On cherche dans ce cas, comme pour la régression multiple, à ce qu’il y ait moins de 1 % de l’échantillon qui se situe à plus de 2 écarts-types ou moins de – 2 écarts-types.
- Corrélation des estimations : tableau de corrélation entre les paramètres estimés des termes dans le modèle. Cette option n’est pas nécessaire.
- Historique des itérations : tableau indiquant les valeurs de la probabilité log à chaque essai d’ajustement du modèle.
- CI pour exp(b) : intervalles de confiance pour le coefficient exp(b).
- Afficher : vous décidez dans cet encadré si vous désirez obtenir les statistiques et diagrammes pour chaque étape du modèle ou seulement pour le modèle final. Idéalement, vous demandez les statistiques à chaque étape pour voir la progression.