RAPPEL THÉORIQUE
La régression logistique propose de tester un modèle de régression dont la variable dépendante est dichotomique (codée 0-1) et dont les variables indépendantes peuvent être continues ou catégorielles. La régression logistique binomiale s’apparente beaucoup à la régression linéaire. Le poids de chaque variable indépendante est représenté par un coefficient de régression et il est possible de calculer la taille d’effet du modèle avec un indice semblable au coefficient de détermination (pseudo R2). Toutefois, elle ne nécessite pas la présence d’une relation linéaire entre les variables puisque la variable dépendante est dichotomique.
Un modèle de régression logistique permet aussi de prédire la probabilité qu’un événement arrive (valeur de 1) ou non (valeur de 0) à partir de l’optimisation des coefficients de régression. Ce résultat varie toujours entre 0 et 1. Lorsque la valeur prédite est supérieure à 0,5, l’événement est susceptible de se produire, alors que lorsque cette valeur est inférieure à 0,5, il ne l’est pas.
Voici quelques exemples de questions de recherche auxquelles peut répondre la régression logistique :
- Est-ce que le nombre d’heures d’études, le niveau d’anxiété et le sexe permettent de prédire la réussite ou l’échec à un examen ?
- Quelle est la probabilité de dépasser son poids santé en adoptant de mauvaises habitudes de vie ?
Généralement, les modèles de régression logistique comprennent plus d’une variable indépendante. Il s’agit donc d’une technique d’analyse multivariée.
Hypothèse nulle
L’hypothèse nulle générale est que la combinaison des variables indépendantes (le modèle) ne parvient pas à mieux expliquer la présence/absence de la variable dépendante qu’un modèle sans prédicteur. Comme c’était le cas pour la régression multiple, la confirmation de cette hypothèse nulle marque la fin de l’interprétation du modèle. Lorsque cette hypothèse nulle est rejetée, ceci signifie qu’il y a au moins un prédicteur du modèle qui est associé significativement à la variable dépendante. Il faut alors interpréter les valeurs des coefficients du modèle (b1, b2, b3… bn) et déterminer lequel ou lesquels sont significatifs.
Les prémisses
1. Les types de variables à utiliser :Indépendantes (prédicteurs) : continue ou catégorielles dichotomiques Dépendante (prédite) : catégorielle dichotomique. Cette dernière doit être une vraie variable dichotomique et non une variable continue recodée en 2 groupes, ce qui serait associé à une importante perte d’information.
2. Inclure les variables pertinentes : toutes les variables pertinentes doivent être comprises dans le modèle et celles qui ne le sont pas, éliminées.
3. Indépendance des observations (VD) et des résiduels : un individu ne peut pas faire partie des deux groupes de la VD (par exemple avec des mesures pré-post-test).
4. Relation linéaire entre les VI et la transformation logistique de la VD
5. Aucune multicolinéarité parfaite ou élevée : il ne doit pas y avoir de relation linéaire parfaite, ni très élevée entre deux ou plusieurs prédicteurs. Par conséquent, les corrélations ne doivent pas être trop fortes entre ceux-ci.
6. Pas de valeurs extrêmes des résiduels : comme dans la régression multiple, des valeurs résidulelles standardisées plus élevées que 2,58 ou moins élevées que -2,58 influencent les coefficients du modèle et limitent la qualité de l’ajustement.
7. Taille de l’échantillon : l’échantillon doit être suffisant pour que l’on puisse procéder à l’analyse. On suggère minimalement 10 observations par variable indépendante (Hosmer et Lemeshow, 1989, voir également Cohen, 1992).
8. Échantillon adéquat pour les prédicteurs catégoriels : lorsqu’une VI catégorielle est croisée avec la VD, aucune cellule ne doit avoir moins d’une observation et un maximum de 20 % des cellules peuvent comprendre 5 observations ou moins. Le modèle : parallèle entre la régression multiple et logistique Nous avons vu que l’équation de la régression multiple est la suivante :
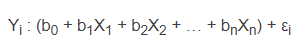
Pour la régression logistique, c’est la même chose, mais en ajoutant la transformation logarithmique. Par exemple, l’équation pour 1 prédicteur est la suivante :
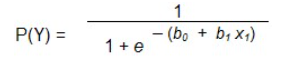
où :
P(Y) est la probabilité que Y arrivee est la base des logarithmes naturels.
Les coefficients b0 et b1 représentent la combinaison linéaire du prédicteur et de la constante.
La régression à plusieurs prédicteurs est donc formulée ainsi :

Il faut toutefois se rappeler que même si la formule se ressemble, on ne peut pas appliquer une régression multiple quand la VD est dichotomique, parce qu’on ne respecte pas la prémisse de relation linéaire.
La transformation logarithmique permet à l’équation de prendre une forme linéaire. Le résultat obtenu à une régression logistique se situera toujours entre 0 et 1. Si la valeur est près de 0, la probabilité est faible que l’événement arrive, alors que si la valeur est près de 1, la probabilité est élevée.
La probabilité maximale
La droite de moindres carrés de la régression linéaire est construite à partir des coefficients qui minimisent la distance au carré entre les points (les valeurs observées) et la droite de régression. Le choix des coefficients de la régression logistique reposent plutôt sur l’obtention des valeurs prédites de Y situées le plus près possible des valeurs observées. Ces coefficients constituent les paramètres d’estimation de la probabilité maximale (maximum-likelihood) et mesurent le changement du ratio de probabilité (odds ratio).
La qualité d’ajustement du modèle : la probabilité log
Comme pour la régression linéaire, l’objectif de la régression logistique est que la variable ajoutée au modèle permette plus efficacement de prédire l’appartenance au groupe que ne le fait le modèle initial (sans prédicteur). La probabilité log (log likelihood), qui s’apparente à la somme des carrés résiduelle (SCR), permet de comparer la valeur observée et prédite pour une personne et ainsi d’évaluer le degré d’imprécision du modèle. Cette probabilité indique quelle proportion de variance il reste à expliquer après avoir intégré le prédicteur au modèle. Lorsque la valeur de la probabilité log reste élevée, le modèle est peu ajusté aux données, puisqu’il demeure beaucoup de variance à expliquer.
La signification de la diminution de la probabilité log est évaluée dans une distribution χ2. La statistique χ2 remplit donc le même rôle que la valeur F et nous indique si le modèle est significatif. On peut ainsi répondre à la question : est-ce que la probabilité log avec seulement la constante est réduite de manière significative lorsque l’on ajoute les prédicteurs ?
Le meilleur prédicteur
Dans la régression logistique, le modèle de base est le plus grand nombre de cas, c’est-à-dire la catégorie (0 ou 1) qui obtient la fréquence la plus élevée. En effet, il ne serait pas judicieux d’utiliser la moyenne comme dans la régression linéaire, puisque la moyenne de 0 et de 1 ne ferait pas de sens. Ainsi, le modèle qui fournit la meilleure prédiction est l’événement qui arrive le plus souvent. Ce dernier est utilisé comme constante.
L’amélioration du modèle est donc calculée à partir de la probabilité -2 log de base (log likelihood value : -2LL), qui illustre la différence au carré entre le modèle de base (la constante ou l’événement qui arrive le plus souvent) et le modèle avec un ou plusieurs prédicteur (s).
χ2 = 2[LL (modèle) – LL (base)]
La différence est mise au carré, car le degré de signification du résultat est évalué à partir de la distribution χ2 (ddl = k-1), où k représente le nombre de paramètres dans le modèle.
R et R2
La statistique R n’est pas fournie par SPSS, mais peut être calculée à la main. Elle représente la corrélation partielle entre chaque VI et la VD et se situe toujours entre – 1 et 1. Lorsque la valence est positive, la valeur du prédicteur augmente en même temps que la probabilité Y, alors que lorsque la valence est négative, la probabilité Y diminue quand la valeur du prédicteur augmente. Plus petite est la valeur calculée, plus faiblement le prédicteur contribue au modèle.

Par contre, la statistique R est calculée à partir de la statistique de Wald, qui sera décrite dans la prochaine section, et de ce fait, doit être interprétée avec prudence. La statistique Wald peut en effet se révéler imprécise dans certaines circonstances, notamment lorsque la taille de l’échantillon est importante. De plus, la statistique R ne peut pas être mise au carrée pour être interprétée comme le R2 de la régression linéaire. On utilise plutôt le Pseudo R2 qui est obtenu à partir de la formule suivante :
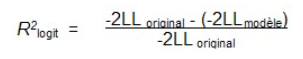
Celui-ci représente la proportion de la probabilité expliquée par l’amélioration du modèle. Sa valeur varie entre 0 et 1.
D’autres indicateurs peuvent aussi être utilisés. Ils sont fournis dans les tableaux de résultats. Le R2L de Hosmer et Lemeshow indique la réduction de la proportion de la valeur absolue de la probabilité log. En ce sens, il s’agit d’une mesure de l’amélioration de l’ajustement du modèle lorsqu’une variable est retirée. Sa valeur varie entre 0 (lorsque la variable indépendante ne permet pas de prédire Y) et 1 (lorsque la variable indépendante prédit parfaitement Y).
Ensuite, le R2 de Cox et Snell (1989) et le R2 Nagelkerke (1991), tous deux fournis dans un tableau SPSS, ces derniers s’apparentent aussi au R2 de la régression linéaire. Le premier n’atteint jamais le maximum théorique de 1 et varie en fonction de la taille de l’échantillon. Le second est une modification du 1er pour obtenir une valeur théorique plus près de 1. Ils mesurent la force de l’association (la taille d’effet) et fournissent un indice de l’ajustement au modèle. Ils représentent un estimé de la variance expliquée par le modèle. Plus leur valeur est élevée, plus la probabilité prédite par le modèle s’approche de la valeur observée.
Le test de Hosmer et Lemeshow (1989)
Ce test évalue la présence de différences significatives entre les valeurs observées et les valeurs prédites pour chaque sujet. Nous cherchons évidemment à ce qu’il ne soit pas significatif. Par contre, il est très sensible à la taille de l’échantillon. De plus, il ne peut pas être calculé lorsque le modèle ne comprend qu’un prédicteur dichotomique. Il doit donc être utilisé à titre indicatif seulement.
Calcul de l’apport de chaque prédicteur : la statistique de Wald
Une fois que nous savons si le modèle est bien ajusté aux données, il est intéressant de connaître l’apport de chaque prédicteur à l’amélioration du modèle. Pour ce faire, nous avons recours à la statistique de Wald. Elle occupe la même fonction que le test-t dans la régression. Elle indique si chaque coefficient beta (b) contribue significativement à l’amélioration du modèle, donc si sa valeur est différente de 0. Elle est évaluée dans une distribution dans une distribution χ2. Cette statistique est calculée ainsi :
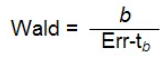
Il est à noter que l’erreur-type est plus grande quand le coefficient b est élevé, il en résulte que la statistique Wald est sous-estimée et peut se révéler non significative même si elle l’est dans la réalité (erreur de type II).
Le changement de proportion : exp b
Occupant une fonction similaire à celle du coefficient b dans la régression linéaire, le coefficient exp b indique le changement de proportion (odds ratio) lorsque le prédicteur X augmente d’une unité. Lorsque la valeur est plus grande que 1, la probabilité augmente avec le changement.
Il faut savoir que la probabilité qu’un événement arrive (odds) est définie comme la probabilité qu’il arrive divisé par celle qu’il n’arrive pas :

On doit donc d’abord calculer
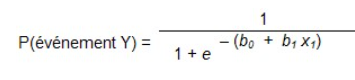
Puis
P(pas événement Y) = 1 – P (événement Y)
Si nous utilisons un exemple concret avec un prédicteur dichotomique pour faciliter la compréhension… nous disons que nous voulons évaluer la probabilité d’avoir la grippe P(Y) en ayant un vaccin (X = 1) et celle d’avoir la grippe sans utiliser le vaccin (X = 0).
Pour obtenir le résultat, nous devons donc remplacer la valeur de b0 et de b1 dans l’équation. Nous effectuons le calcul en remplacant X par 0 pour obtenir la probabilité originale (odds), soit le rapport entre la probabilité d’avoir la grippe et de ne pas avoir la grippe lorsque nous n’avons pas de vaccin.
Ensuite, nous reprenons le calcul avec le changement d’une unité du prédicteur, donc en remplacant X par 1. Cette probabilité représentera le rapport entre la probabilité d’avoir la grippe et celle de ne pas avoir la grippe lorsque nous recevons un vaccin.
À partir de ce moment, nous pourrons calculer le changement de proportion, soit la valeur de exp b.

Les méthodes de régression
Les méthodes de régression disponibles sont les mêmes que pour la régression linéaire. Toutefois, le critère de sélection pour les méthodes progressives est différent.
Vous pouvez donc opter pour la méthode Entrée et insérer toutes les variables prédictrices en même temps. De plus, si vous préférez sélectionner l’ordre d’entrée des variables, choisissez la méthode hiérarchique. Les paramètres seront calculés pour chaque bloc de variables.
Parmi les méthodes progressives, vous avez toujours le choix entre ascendante ou descendante. Dans la méthode ascendante, SPSS introduit la variable ayant le score le plus élevé en premier jusqu’à ce qu’aucune variable n’ait une statistique score significative (soit plus petit que 0,05). Dans la méthode descendante, le contraire se produit puisque le premier modèle évalué contient toutes les variables et SPSS retire celles qui ne contribuent pas significativement à l’amélioration de la prédiction. La différence avec la régression multiple est que SPSS évalue à chaque étape si certaines variables devraient être retirées en se basant sur :
- Le rapport de vraisemblance (likelihood-ratio, LR) : SPSS conserve la variable si le changement du LR est significatif quand la variable est retirée, ce qui indique que cette variable contribue à la qualité de l’ajustement;
- La statistique conditionnelle : il s’agit d’un critère moins exigeant que le LR, donc il est préférable de prioriser le 1er;
- La statistique Wald : cette fois, SPSS retire toutes les variables pour lesquelles la statistique Wald est inférieure à 0,1. Cette méthode peut être utilisée avec un petit échantillon. Sinon, il est préférable de privilégier le LR.