1. Pour réaliser l’analyse, cliquez sur Analyse, Régression, puis Linéaire.
2. En cliquant sur la flèche, insérez la variable dépendante et la ou les variable(s) indépendante(s) dans les boîtes appropriées.
3. Si vous désirez absolument que la première variable indépendante soit incluse, privilégiez la méthode Entrez.
4. Pour créer des blocs (groupes) de variable(s) indépendante(s) dans le cadre d’une régression hiérarchique, cliquez sur SUIVANT lorsque le premier bloc est construit, puis insérez les variables indépendantes des autres blocs en répétant cette procédure. La méthode de régression (Entrée, Pas à pas, etc.) peut être déterminée pour chaque bloc. Habituellement, la méthode Entrez est utilisée à moins d’a priori théoriques particuliers.
5. Vous pouvez choisir une variable de filtrage pour limiter l’analyse à un sous-échantillon formé par les participants ayant obtenu une ou des valeur(s) particulière(s) à cette même variable.
6. Vous pouvez aussi spécifier une variable qui permettra d’identifier les coordonnées sur le graphique (Étiquettes d’observation).
7. Enfin, vous pouvez choisir une variable numérique pondérée (Poids WLS) pour effectuer l’analyse des moindres carrés. Par cette analyse, les valeurs sont pondérées en fonction de leurs variances réciproques, ce qui implique que les observations avec de larges variances ont un impact moins important sur l’analyse que les observations associées à de petites variances.
8. Assurez-vous d’avoir sélectionné les options nécessaires (par exemple, sous le bouton Statistiques).
9. Pour procéder à l’analyse, cliquez sur OK.
Une présentation détaillée de toutes les options est disponible dans le procédurier de la régression simple.
Le bouton STATISTIQUES
Pour la régression multiple, nous suggérons de cochez les options suivantes :
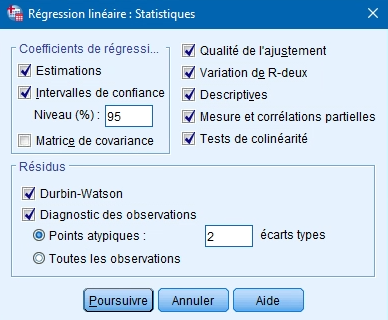
L’encadré Coefficients
- Estimations : valeurs b pour chaque VI et son test de signification
- Intervalles de confiance : intervalle pour chaque coefficient dans la population
L’encadré Résidus
- Durbin-Watson : évaluation de l’indépendance des erreurs
- Diagnostic des observations : valeur de la VD observée, prédite, du résiduel et du résiduel standardisé pour chaque observation. Indique quelles observations ont un résiduel standardisé de plus de 2 ou 3 é.-t. (au choix de l’utilisateur)
Les autres statistiques
- Qualité de l’ajustement : fournit le test pour évaluer l’ensemble du modèle (F), le R multiple, le R2 correspondant et le R2 ajusté
- Variation de R-deux : changement du R2 après l’ajout d’un nouveau bloc de VI
- Caractéristiques : moyenne, é.-t. et N pour toutes les variables du modèle
- Mesure et corrélations partielles :
- Corrélation entre chaque VI et la VD
- Corrélation partielle entre chaque VI et VD en contrôlant pour les autres VI
- Corrélation « partie » ou semi-partielle entre chaque VI et la variance non expliquée de la VD par les autres VI
- Test de colinéarité : évaluation de la multicolinéarité dans le modèle (VIF).
Cliquez sur POURSUIVRE pour revenir à la boite de dialogue principale.
Le bouton TRACÉS
Les graphiques offerts permettent de vérifier par un examen visuel les prémisses de la régression linéaire multiple. Celui croisant les valeurs prédites (*ZPRED) et résiduelles (*ZRESID) standardisées illustre le respect (ou le non respect) de la prémisse d’homogénéité (répartition aléatoire des points autour de 0) et de linéarité (tendance des points à se concentrer autour d’une ligne).
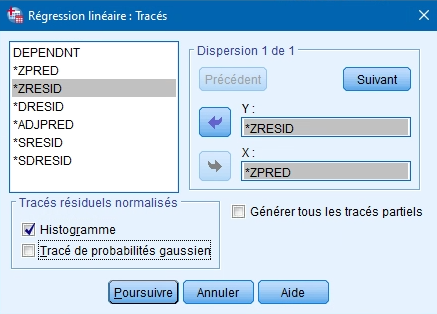
Pour faire plus d’un graphique, utilisez le bouton SUIVANT.
L’encadré des diagrammes des résidus normalisés permet d’illustrer la distribution des résiduels (histogramme et diagrammes de répartition gaussiens), ce qui vous permet de faire un examen visuel du respect de la prémisse de normalité de la distribution des erreurs.
Cliquez sur POURSUIVRE pour revenir à la boîte de dialogue principale.
Le bouton ENREGISTRER
Toutes les options disponibles dans ce menu permettent de créer des nouvelles variables ayant les valeurs calculées par le modèle. Il s’agit donc de choisir les variables diagnostiques permettant d’évaluer la qualité du modèle et celles qui permettent de détecter les variables ayant une importante influence sur le modèle. On choisira donc minimalement les résidus standardisés, mais on peut également ajouter les valeurs prédites non standardisées et standardisées (valeur de la VD calculée pour chaque observation) ainsi que la distance de Cook et les DfBêta(s) standardisés. Notez qu’en cochant des options dans la boîte de dialogue Enregistrer, vous allez obtenir un tableau de résultats de plus portant sur les statistiques des résidus et comprenant minimalement la moyenne, l’écart-type, les valeurs minimales et maximales ainsi que le N.
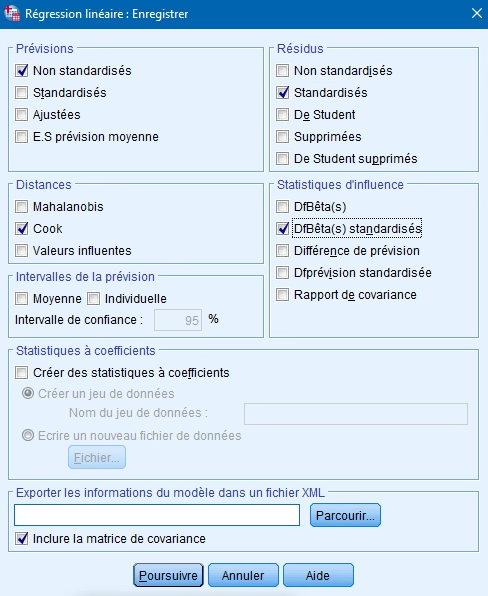
Cliquez sur POURSUIVRE pour revenir à la boîte de dialogue principale.
Le bouton OPTIONS
La dernière fenêtre vous permet de déterminer les paramètres de sélection des méthodes d’entrée progressives (Ascendante ou descendante – stepwise). Vous pouvez utiliser la valeur de la probabilité associée à la valeur F (soit la valeur de p) ou encore la valeur de la statistique F pour introduire ou retirer des variables. Idéalement, vous conservez les valeurs par défaut à moins que vous ne vouliez que les critères d’entrée ou de retrait des variables de votre modèle soient plus sévères ou plus inclusifs.
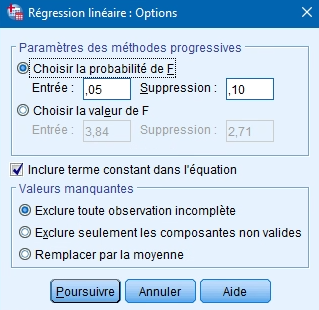
Évidemment, vous laissez aussi la constante dans l’équation. Vous pouvez finalement spécifier ce que vous désirez faire avec les valeurs manquantes. Encore une fois, l’option par défaut est à privilégier puisque le retrait de toute observation incomplète permet de conserver toujours le même nombre d’observations, ce qui favorise la cohérence du modèle.
Cliquez sur POURSUIVRE pour revenir à la boite de dialogue principale.