Dans notre exemple, nous voulons savoir quelles variables influencent le salaire annuel d’un employé (SALAIRE). La théorie nous indique que le nombre d’années de scolarité a une importante influence (EDUC). Nous désirons savoir si le sexe des employés (SEXE) et le nombre de mois d’expérience dans l’entreprise (DURÉE) exercent également une influence. Nous avons donc choisi un modèle de régression hiérarchique (comprenant deux blocs de variables) avec la méthode entrée pour la première étape (bloc 1 avec EDUC), mais la méthode ascendante pour la deuxième (bloc 2 avec SEXE et DURÉE), dans le but d’illustrer les différentes possibilités de modélisation.
Statistiques descriptives
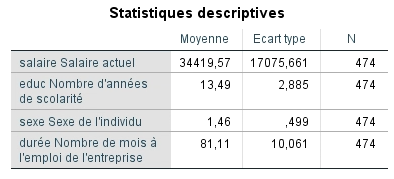
Examinons d’abord les statistiques descriptives. Nous voyons que l’étude a été menée auprès de 474 employés qui gagnent en moyenne actuellement près de 35 000 $. Ils travaillent depuis environ sept ans pour leur entreprise (81 mois) et ont en moyenne 13 ans de scolarité. Bien entendu, la moyenne des hommes et des femmes n’est pas une donnée pertinente, mais elle indique que la variable a été codée 1-2. Idéalement, les variables dichotomiques doivent toujours être codées 0-1 pour en faciliter l’interprétation.
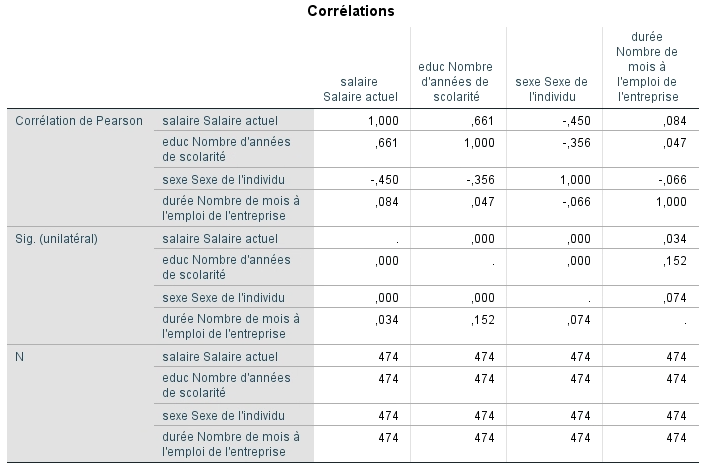
Le deuxième tableau fourni par SPSS concerne les corrélations entre les variables étudiées. Nous voyons qu’il y a une corrélation très élevée et significative entre le salaire et le nombre d’années de scolarité, ainsi qu’entre le sexe et le salaire. On doit porter attention aux relations entre les variables indépendantes. Si la corrélation entre deux de ces variables se situait à 0,9 (ou – 0,9), il y aurait un risque important de multicolinéarité. Nous aurions introduit deux variables qui mesurent sensiblement la même chose pour prédire le salaire actuel. Nous voulons éviter cette situation.
Variables introduites/éliminées
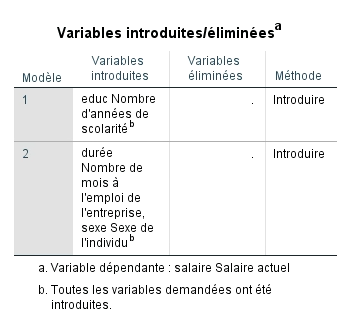
Le tableau suivant présente les variables retenues dans les deux étapes du modèle. On constate que la variable EDUC est forcément présente puisque nous avions choisi la méthode Entrée. Pour le deuxième bloc du modèle, SPSS a retenu la variable SEXE avec notre critère de sélection (la probabilité F est significative à p < 0,05) et a exclu la variable DURÉE, car la valeur F associée au coefficient b n’atteint pas le seuil de signification.
Étape 1 : Évaluation de la qualité du modèle de régression
Tout comme la régression simple, l’interprétation débute en évaluant la qualité du modèle. On vérifie si la première étape du modèle explique significativement plus de variabilité qu’un modèle sans prédicteur (VI). Ensuite, il s’agit de s’assurer que toutes les variables introduites contribuent à améliorer significativement la variabilité expliquée par le modèle final.
Analyse de variance
Le tableau d’ANOVA nous donne cette information. Il nous permet de déterminer si nous rejettons l’hypothèse nulle (H0) ou non. Dans notre exemple, nous voulons savoir dans un premier temps si le nombre d’années de scolarité prédit mieux le SALAIRE que ne le fait un modèle sans prédicteur (avec seulement la moyenne) et dans un deuxième temps, si le nombre d’années de scolarité et le sexe prédisent mieux le SALAIRE qu’un modèle sans prédicteur. L’hypothèse nulle est donc que les deux modèles sont équivalents à la moyenne du salaire.
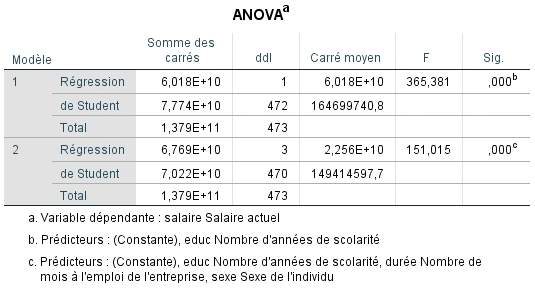
On constate à la lecture du tableau que selon la valeur F obtenue pour les deux modèles, on peut rejeter l’hypothèse nulle. En effet, les valeurs de 365,38 et de 225,51 sont significatives à p < 0,001, ce qui indique que nous avons moins de 0,1 % de chance de se tromper en affirmant que les modèles contribuent à mieux prédire le salaire que la simple moyenne.
Étape 2 : Évaluation de l’ajustement du modèle de régression aux données
Maintenant que l’on sait que le modèle est significatif, le tableau récapitulatif des modèles permet de déterminer la contribution de chaque bloc de variables. Ce tableau indique le R2 cumulatif à chaque étape du modèle (colonne R-deux)) ainsi que l’apport spécifique de chaque bloc (colonne Variation de R-deux).
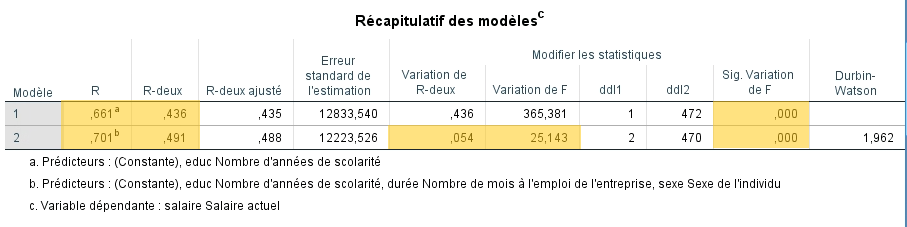
Le tableau contient donc plusieurs informations utiles. Premièrement, la valeur de la corrélation multiple (R) correspond à l’agglomération des points dans la régression simple. Elle représente la force de la relation entre la VD et la combinaison des VI de chaque modèle. Des valeurs de 0,66 et 0,70 suggèrent que les données sont ajustées de manière satisfaisantes au modèle.
Ensuite, la signification du R2 est évaluée en fonction de l’apport de chaque étape. La variation de F associée au premier modèle est significative (p < -.001). Ce modèle explique donc une proportion significative de la variance de la variable SALAIRE. Nous sommes passés de R2 = 0 à R2 = 0,436. Le deuxième modèle fait passer le R2 de 0,436 à 0,489. Cette variation de 0,053 apparait comme significative. En effet, la valeur de F est calculée à partir de la varaition du R2 entre les étapes. SPSS détermine donc si la différence (0,053) entre le R2 du modèle 2 (0,489) et celui du modèle 1 (0,436) est significative. Cette fois-ci, c’est le cas (p < 0,001). Chaque étape contribue donc significativement à l’amélioration de l’explication de la variabilité de la VD.
La dernière colonne concerne le test de Durbin-Watson, il n’y a pas de seuil de signification associé, seulement la valeur de la statistique qui est acceptable lorsqu’elle se situe entre 1 et 3. Il est convenu que plus la valeur est près de 2, moins il y a de problème au niveau de l’indépendance des erreurs. Avec une valeur de 1,96, nous pouvons croire que nous respectons cette prémisse.
Étape 3 : Évaluation de la variabilité expliquée par le modèle de régression
Enfin, on se rappelle que la valeur du R2, lorsqu’elle est multipliée par 100, indique le pourcentage de variabilité de la VD expliquée par le modèle (les prédicteurs). Les résultats suggèrent que 43,6 % du salaire est expliqué par le nombre d’années de scolarité et que 48,7 % du salaire est expliqué par la combinaison de la scolarité et du sexe de l’employé.
Étape 4 : Évaluation des paramètres du modèle
Maintenant que nous savons que notre modèle est significatif et que le deuxième est celui qui explique le plus de variance, il est possible de construire l’équation de régression pour prédire une valeur de Y. L’équation de base était la suivante :
Yi : (b0 + b1X1 + b2X2 + … + bnXn) + εi
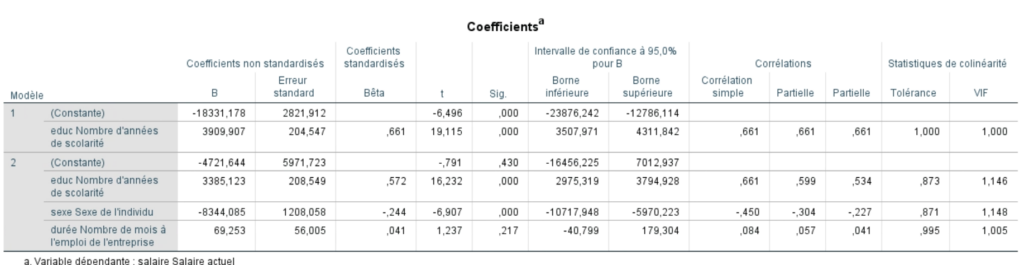
Remplaçons maintenant les b par les coefficients fournis dans le tableau ci-dessous.
Yprédit = (-7900,99 + 3391,68educ – 8423,46sexe)
Pour un homme ayant complété 16 années de scolarité, nous obtiendrions un salaire prédit de…
Yprédit = (-7900,99 + 3391,68*16 – 8423,46*1)
Yprédit = 37 942,43 $ par année
Le signe du coefficient nous indique le sens de la relation. Dans notre cas, plus le nombre d’années de scolarité augmente, plus le salaire augmente. Nous voyons aussi que quand le sexe diminue (passant de 2 pour les femmes à 1 pour les hommes), le salaire augmente.
Le coefficient nous informe également sur le degré auquel chaque prédicteur influence la VD si tous les autres prédicteurs sont constants. Par exemple, chaque année de scolarité de plus est associée à 3 391,68 $ de plus annuellement.
L’erreur standard nous renseigne sur la variabilité du coefficient dans la population. Elle permet également de calculer la valeur de t. Cette dernière nous indique si le coefficient est significatif. Alors que le tableau sur le récapitulatif des modèles confirmait si chaque modèle était significatif, la signification de t nous permet de répondre à la question « est-ce que le b du prédicteur est différent de 0 ? », donc si chaque variable contribue significativement au modèle. Plus la valeur de t est élevée et plus celle de p est petite, plus le prédicteur contribue au modèle. Nous constatons donc que les deux variables sont significatives, mais que la variabilité expliquée par le nombre d’années de scolarité est plus importante que celle expliquée par le sexe.
La valeur du Beta standardisé (β) apporte aussi une information intéressante. Elle indique le changement en écart-type de la VD pour chaque augmentation d’un écart-type de la VI quand toutes les autres valeurs sont constantes. Par exemple, la valeur d’un écart-type du salaire est de 17 075,66 $ et celle d’un écart-type de scolarité est de 2,89. Nous pouvons donc savoir que l’augmentation d’un é.-t. de la scolarité (2,89) est associé à l’augmentation de 0,57 é.-t. du salaire (0,57*17 075,66 = 9 733,13). Par conséquent, chaque fois que l’on étudie 2,89 années de plus, le salaire augmente de 9 733,13 $.
Pour les intervalles de confiance, nous voulons obtenir les valeurs les plus rapprochées pour que le modèle soit le plus près possible des données réelles de la population. Il ne faut absolument pas que la valeur 0 se situe entre les deux intervalles, car cela signifierait qu’une différence de 0 est une valeur possible. DAns ce cas, la valeur de t forcément non significative.
Ce tableau présente également la valeur des corrélations et des corrélations partielles. Ce sont ces valeurs sur lesquelles se base SPSS lorsqu’il choisit d’introduire des variables lorsque l’on sélectionne une méthode d’entrée progressive. La première variable est choisie à partir de la corrélation simple la plus forte (ici 0,661 pour EDUC). Le choix des variables suivantes est par contre basé sur la corrélation partielle, c’est-à-dire la plus forte corrélation entre les variables toujours disponibles et la partie de variance qui reste à expliquer une fois que l’on a retiré ce qui est expliqué par le premier prédicteur.
Finalement, la valeur VIF (ou la tolérance, soit l’inverse du VIF (1/VIF)) permet de vérifier la prémisse de multicolinéarité. Nous cherchons à obtenir une valeur VIF près de 1. Si elle est de 10, c’est problématique. Conséquemment, si la tolérance est équivalente à 0,1, il y a un problème sérieux . Probablement que les corrélations entre 2 variables prédictrices ou plus sont trop élevées.
Les variables exclues
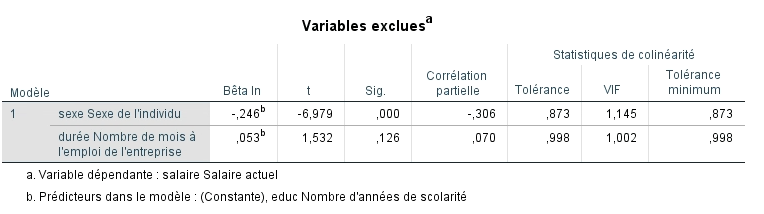
Le tableau suivant présente les variables qui n’ont pas été retenues dans le modèle à chacune des étapes. La valeur b est estimée pour chaque variable si cette dernière était incluse. Si la valeur de t est significative, nous pouvons comprendre que l’ajout de cette variable contribuerait probablement à l’amélioration du modèle. SPSS évaluera d’abord l’apport de la variable ayant la valeur t la plus élevée dans une régression progressive. La corrélation partielle donne également un indice de la contribution au modèle. C’est la même valeur que l’on trouvait dans le tableau précédent.
Le diagnostic des observations et la vérification des prémisses
Ce dernier tableau est fourni grâce aux options sélectionnées préalablement. Il nous renseigne sur la présence de valeurs extrêmes qui influenceraient le modèle, donc sur la qualité de l’ajustement des données. Les valeurs extrêmes font varier les coefficients b et sont mal prédites par le modèle, donc elles sont associées à une valeur résiduelle importante. Comme nous avons vu précédemment dans le rappel théorique, nous ne voulons aucune valeur résiduelle standardisée de plus de 3,29 (ou de moins de -3,29), pas plus de 1 % de l’échantillon ayant une valeur de plus de 2,58 (ou de moins de -2,58) ainsi qu’un maximum de 5 % des observations ayant une valeur de plus de 1,96 (ou de moins de – 1,96).
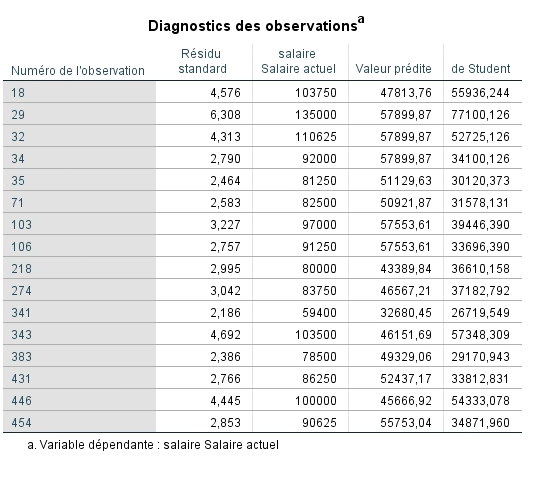
En observantt le diagnostic des observations, nous constatons que 7 individus ont des salaires de plus de 83 750 $. Ils s’écartent vraiment de la moyenne, la valeur résiduelle standardisée pour chacun est de plus de 3 écart-types. Les employés gagnant plus de 100 000 $ annuellement présentent un problème majeur. Il serait probablement judicieux de refaire l’analyse en excluant ces hauts salariés et de vérifier la variation des coefficients.
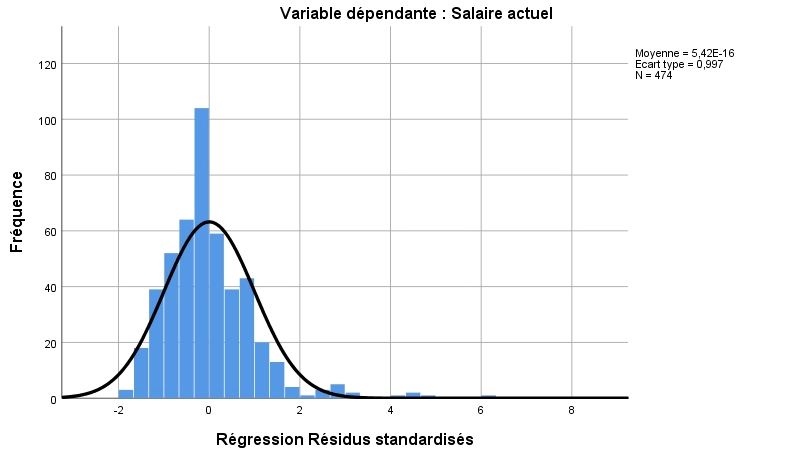
D’ailleurs, nous pouvons constater en regardant l’histogramme de la distribution des valeurs résiduelles que nous ne respectons pas la prémisse de normalité de distribution des erreurs. Nous souhaitons que la distribution suive une courbe normale, mais nous observons un pic prononcé ainsi que des valeurs éloignées de la courbe. Cette distribution n’est donc probablement pas normale. Nous pourrions confirmer avec le test de normalité de Shapiro-Wilks ou de Kolmogorov-Smirnoff. Ces tests sont disponbiles dans les options de la procédure Explorer. Cochez Graphes de répartition gaussiens avec tests. Cela nous confirme encore qu’il pourrait être judicieux de retirer ces valeurs extrêmes de l’analyse.
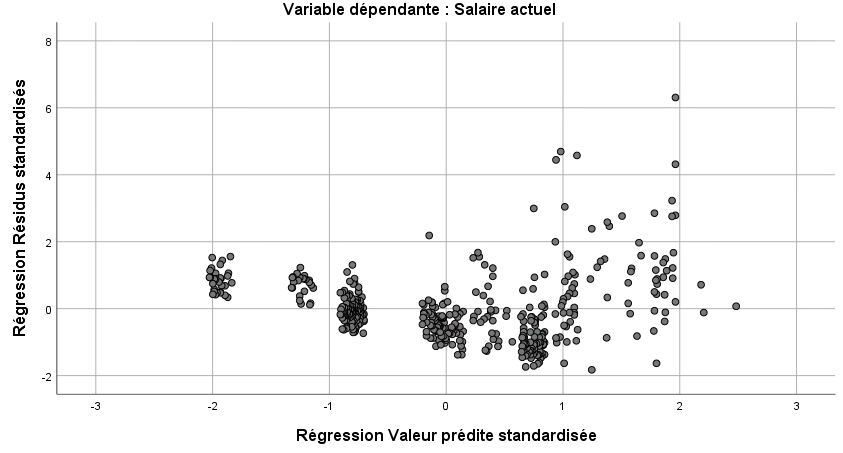
Finalement, nous pouvons tout de même jeter un coup d’œil aux prémisses d’homéodasticité et de linéarité avec le graphique de dispersion. Pour la première prémisse, les points doivent être répartis aléatoirement autour de 0 (ne pas former d’entonnoir), ce qui semble le cas ici, bien que les points soient répartis en colonnes. Pour la deuxième, nous voulons éviter que l’agglomération de points suive une courbe. Cette prémisse semble aussi respectée. Nous respectons donc la plupart des prémisses, le modèle est donc probablement valide, mais gagnerait certainement en précision en éliminant les valeurs extrêmes.