RAPPEL THÉORIQUE
En général, les modèles de régression sont construits dans le but d’expliquer (ou prédire, selon la perspective de l’analyse) la variance d’un phénomène (variable dépendante) à l’aide d’une combinaison de facteurs explicatifs (variables indépendantes). Dans le cas de la régression linéaire multiple, la variable dépendante est toujours une variable continue tandis que les variables indépendantes peuvent être continues ou catégorielles. La régression linéaire est appelée multiple lorsque le modèle est composé d’au moins deux variables indépendantes. À l’inverse, un modèle de régression linéaire simple ne contient qu’une seule variable indépendante. Comme il est excessivement rare, voire impossible, de prédire un phénomène à l’aide d’une seule variable, cette section porte sur la régression linéaire multiple. Cependant, tout le contenu s’applique également aux résultats d’une régression simple.
Nous allons donc voir maintenant comment il est possible d’expliquer (ou de prédire) la variance d’une variable dépendante à l’aide d’une combinaison linéaire de variables indépendantes à partir de la généralisation de l’équation algébrique utilisée dans le module sur la régression simple.
Les questions auxquelles la régression linéaire multiple permet de répondre sont nombreuses. Par exemple,
- Quelles variables permettent de prédire les symptômes anxieux ?
- De combien le risque de chutes va diminuer chez les personnes âgées lorsqu’elles participent à des exercices de groupe, un suivi individuel et changent leurs habitudes de vie ?
- Est-ce que la satisfaction au travail varie en fonction de l’augmentation des défis à relever et de l’esprit d’équipe ?
- Quelle proportion de la variance du taux de décrochage est expliquée par la combinaison des variables prédictives ?
Hypothèse nulle
L’hypothèse nulle est qu’il n’y a pas de relation linéaire entre la combinaison des variables indépendantes (X1, X2, X3… Xn) et la variable dépendante (Y).
L’hypothèse de recherche est l’inverse, soit que la combinaison des variables indépendantes est associée significativement à la variable dépendante.
Les prémisses
1. Les types de variables à utiliser :
Indépendantes : continue ou catégorielle (ordinale ou dichotomique)
Dépendante : continue
2. Pas de variance égale à zéro : la distribution des prédicteurs doit comprendre une certaine variance, donc ne doit pas être constante.
3. Aucune multicolinéarité parfaite : il ne doit pas y avoir de relation linéaire parfaite entre deux ou plusieurs variables indépendantes. Par conséquent, les corrélations ne doivent pas être trop fortes entre celles-ci. Cette prémisse peut être vérifiée avec le VIF (Variance Inflation Factor) indiquant si une variable indépendante a une une relation linéaire forte avec les autres. La règle arbitraire souvent appliquée veut qu’une valeur de cet indice plus grande que 10 indique la présence d’un tel problème.
4. Pas de corrélation entre les variables indépendantes et les variables externes : les variables d’influence doivent toutes être incluses dans le modèle.
5. Homéocédasticité (homogénéité des variances des résiduels) : la variance des valeurs résiduelles doit être similaire à tous les niveaux de la variable indépendante.
6. Indépendance des erreurs : les valeurs résiduelles ne doivent pas être corrélées entre les individus. Cette prémisse peut être vérifiée avec la statistique Durbin-Watson qui se situe entre 0 et 4, une valeur de 2 indiquant une absence de corrélation, moins de 2 une corrélation positive et plus de 2, une corrélation négative. La règle arbitraire cette fois est que la valeur ne doit pas être plus petite que 1 ou plus grande que 3.
7. Distribution normale des résiduels : bien que les variables indépendantes ne doivent pas nécessairement suivre une distribution normale, il importe que les résiduels en suivent une. Ils doivent donc avoir une moyenne de 0, la majorité des valeurs doivent s’en rapprocher. Cette prémisse peut être vérifiée en enregistrant les valeurs résiduelles dans la base de données et en effectuant le test de Kolmogorov-Smirnov ou de Shapiro-Wilks, disponible dans les options de la commande Explorer. Vous devez vous assurer que le test n’est pas significatif pour conserver l’hypothèse nulle de distribution normale.
8. Indépendance de la variable prédite : toutes les observations formant la distribution des valeurs de la variable dépendante sont indépendantes, viennent d’un individu différent.
9. Relation linéaire entre les variables indépendantes et la variable dépendante : la variation de la variable dépendante pour chaque augmentation d’une unité d’une variable indépendante suit une ligne droite.
Le modèle multivarié
De manière générale, les modèles statistiques se présentent globalement ainsi :

Chaque valeur de la variable dépendante (Observationi) peut être expliquée en partie par un modèle statistique. La partie que le modèle ne peut expliquer est l’erreur spécifique associée à cette valeur.
Dans le cas de la régression linéaire simple, ce modèle général peut se décliner plus précisément ainsi :
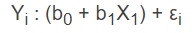
Où Y représente les valeurs possibles de la variable dépendante qui peuvent être expliquées par le modèle général de régression. Encore une fois, la portion qui ne peut être expliquée par le modèle est symbolisée par εi qui représente l’erreur commise par le modèle pour chaque valeur de Y.
L’équation de la régression linéaire multiple est en fait la généralisation du modèle de régression simple.
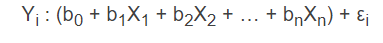
On observe que chaque variable indépendante (X) est multipliée par son propre coefficient bêta (b) qui sous sa forme standardisée correspond à sa contribution relative dans le modèle. La constante (b0) correspond à la valeur de la variable dépendante lorsque toutes les variables indépendantes égalent 0. On appelle aussi b0 l’ordonnée à l’origine. Associée de près à l’évaluation du modèle, l’indice de corrélation multiple R2 représente le pourcentage de variance expliquée par le modèle (la combinaison des variables indépendantes).
La conception d’un modèle de régression
La conception d’un modèle de régression ne devrait jamais être prise à la légère. Elle devrait faire l’objet d’une réflexion préalable portant sur 1) le choix des variables indépendantes et 2) le choix de la méthode de régression.
Le choix des variables indépendantes
En tout temps, le choix des variables indépendantes doit être guidé par le principe de parcimonie qui veut qu’un bon modèle comprend un nombre optimal de variables et par la présence d’un lien théorique connu ou présumé avec la variable dépendante. Voici d’autres éléments à considérer lors du choix des variables indépendantes. Cette liste n’est pas exhaustive, mais souligne l’importance des éléments à considérer lors de cette étape.
1. La nature des objectifs ou des hypothèses de recherche : Les variables mises en cause dans l’énoncé d’un objectif ou d’une hypothèse doivent forcément se retrouver dans le modèle. L’énoncé peut également avoir un impact sur le choix de la méthode de régression.
2. La présence de variables confondantes : Il est possible que certaines variables n’apparaissant pas dans l’énoncé de l’objectif ou de l’hypothèse soient importantes dans un modèle dans la mesure où elles peuvent influencer les résultats. On appelle ces variables « confondantes » et leur inclusion dans le modèle permet de contrôler statistiquement leur effet.
3. La présence de corrélation avec la variable dépendante : Dans certains contextes, il est possible de choisir les variables indépendantes en fonction de leur degré d’association avec la variable dépendante. Des variables n’ayant pas de lien assez fort avec celle-ci pourrait être exclues du modèle.
4. La puissance statistique du devis : Cohen (1992) et Hair et al. (2005) ont bien démontré que le nombre d’observations détermine la quantité maximale de variables qu’un modèle peut supporter. Plus on a d’observations, plus on peut inclure de variables dans le modèle.
Le choix de la méthode de régression
La méthode de « construction » d’un modèle de régression nécessite également une réflexion préalable. En effet, la méthode choisie ne sera pas la même selon que l’on désire tester un modèle théorique précis, contrôler l’effet de variables confondantes ou tout simplement explorer une combinaison particulière de variables indépendantes. De même, la façon d’introduire les variables ou les blocs de variables indépendantes dans ce modèle doit faire également l’objet d’une justification rationnelle.
Dans un premier temps, on doit choisir une des deux stratégies suivantes : la modélisation globale ou la modélisation par blocs. Dans le premier cas, la combinaison de toutes les variables est évaluée globalement. Dans le second, les variables sont regroupées en bloc et les résultats évaluent le modèle global ainsi que la contribution de chaque bloc.
Dans un deuxième temps, on doit également déterminer la manière dont les variables indépendantes seront insérées dans le modèle global ou dans les blocs : par entrée forcée ou par entrée progressive.
Voyons maintenant la description plus précise des méthodes pour lesquelles vous pourriez opter une fois que les variables indépendantes ont été choisies.
1. La régression hiérarchique (hierarchical regression)
Cette méthode permet au chercheur de déterminer l’ordre d’entrée des variables dans le modèle à l’aide de la création des blocs de variables qui seront entrés de manière hiérarchisée dans le modèle. Ceci permet d’observer plus en détail comment se comporte le modèle. Les résultats indiquent l’apport de chaque bloc en termes de pourcentage de variance expliquée (R2). Pour les blocs constitués de plus d’une variable, il est possible de faire entrer celles-ci en un seul temps (entrée forcée) ou progressivement (voir plus bas).
2. La régression avec entrée forcée
Cette fois-ci, toutes les variables évaluées sont entrées au même moment et un test F évalue l’ensemble du modèle. Le choix des variables à inclure repose encore sur la théorie. Par contre, le chercheur n’influence pas l’ordre d’entrée des variables. Le modèle évalue donc leur effet combiné.
3. La régression avec entrée progressive
Contrairement aux deux autres méthodes, la sélection des variables à inclure est basée sur un critère mathématique. Une fois les variables indépendantes choisies, leur inclusion dans le modèle dépendra de leur contribution mathématique à son amélioration. Il existe trois méthodes progressives.
La première est la méthode ascendante (forward). Dans ce cas, le modèle initial ne contient que la constante (b0). Celui-ci servira de base de comparaison pour déterminer si l’ajout d’une variable contribue significativement à l’amélioration du modèle. SPSS choisit parmi les variables indépendantes soumises celle qui a la plus forte corrélation avec la variable dépendante. Il évalue si cet ajout est significatif. Si c’est le cas, il intègre une deuxième variable. Cette dernière a la plus forte corrélation partielle avec la variable dépendante. On parle de corrélation partielle puisque le calcul est effectué avec la variance de la variable dépendante qui reste à expliquer une fois que l’effet de la première variable est retiré. SPSS évalue ensuite si l’ajout de cette variable est significatif. Si c’est le cas, il la retient et détermine s’il peut ajouter un 3e prédicteur. Il cesse d’inclure des nouvelles variables lorsque l’augmentation de la valeur de R2 n’est plus significative.
La deuxième est la méthode pas-à-pas (stepwise). Celle-ci ressemble beaucoup à la méthode ascendante, puisque le choix de la première variable est encore basé sur la corrélation la plus élevée et celui des variables suivantes sur la corrélation partielle. Toutefois, lorsque SPSS ajoute une variable au modèle, il évalue si elle apporte une contribution significative, mais également si celle qui contribuait le moins au modèle demeure significative. Si ce n’est pas le cas, il la retire. De cette manière, il est possible d’éliminer les variables redondantes.
Enfin, la dernière est la méthode descendante (backward). Dans ce cas, le modèle initial comprend toutes les variables, comme pour la régression forcée. SPSS va cette fois retirer la variable ayant la plus faible contribution au modèle si la variation du R2 n’est pas significative en l’éliminant. La procédure va être répétée jusqu’à ce que toutes les variables conservées contribuent significativement à l’amélioration du R2.
Quelle méthode privilégier ?
Parmi toutes ces méthodes, laquelle devrions-nous privilégier ? De manière générale, on suggère qu’un modèle bien balisée par la théorie devrait utiliser une stratégie globale avec une méthode d’entrée forcée, hiérarchisée ou non. Pour les travaux de nature davantage exploratoire, les méthodes progressives sont adaptées. Parmi les trois présentées, on privilégiera la méthode descendante, car il y a plus de risques de commettre des erreurs de type II avec la méthode ascendante. Celle-ci ne tient pas compte des variables significatives lorsqu’elles sont combinées et peut donc plus facilement oublier une variable qui affecte la variable dépendante en présence d’un autre prédicteur.
Enfin, un bon modèle sera parcimonieux, constitué de variables ayant une pertinence théorique et expliquera une proportion satisfaisante de la variance de la variable dépendante.
La régression hiérarchisée est intéressante lorsque le modèle comporte plusieurs variables qui peuvent être théoriquement regroupées ou lorsque certaines variables doivent être contrôlées statistiquement (ex. : variables socioéconomiques). SPSS permet de regrouper ces variables en « blocs » dont l’ordre d’inclusion devrait représenter leur position relative (proximale ou distale) par rapport à la variable dépendante. Le premier bloc doit contenir les variables contrôles ou encore les variables proximales et les blocs subséquents comprennent les variables de plus en plus distales. SPSS donne les résultats pour le modèle global (toutes les variables) ainsi que l’apport spécifique de chaque bloc une fois l’effet du bloc précédent considéré.
Le diagnostic des observations
Une fois que la méthode de régression est choisie, il est important également de considérer si le modèle qu’on va obtenir est bien ajusté aux données ou s’il est influencé par la présence de valeurs extrêmes, qui s’écartent beaucoup des autres observations.
Comme pour toute analyse statistique, il est préférable d’examiner au préalable les distributions des variables qui seront mises en cause. Les procédures descriptives permettent entre autres d’identifier les valeurs extrêmes. Ces dernières influencent grandement le modèle, elles peuvent faire varier les coefficients beta de l’équation qui sera, de ce fait, moins précise. Il importe donc de savoir si des valeurs extrêmes sont présentes.
Une autre stratégie simple consiste à déterminer pour quelles observations les valeurs résiduelles sont importantes. En effet, si une valeur extrême est présente, son score prédit sera très différent de la valeur observée. En corollaire, on peut ajouter que plus les valeurs résiduelles de l’ensemble des observations sont petites, mieux le modèle de régression est ajusté aux données.
Les valeurs résiduelles sont calculées dans la même unité de mesure que la variable originale. Afin de faciliter la comparaison entre les modèles, on transforme ces valeurs en score Z (résiduels standardisés), ce qui nous permet plus facilement d’identifier quelles sont les valeurs très éloignées du modèle. On se base sur les balises de la courbe normale pour déterminer quelles sont les valeurs extrêmes. Dans un modèle bien ajusté, on s’attend à trouver
Moins de 5 % des résiduels standardisés ayant une valeur > 1,96 ou < -1,96
Moins de 1 % des résiduels standardisés ayant une valeur > 2,58 ou < -2,58
Aucun résiduel standardisé ayant une valeur de > 3,29 ou < -3,29
Sinon, on doit porter une attention très particulière aux résiduels ayant des valeurs de plus de 3 (3,29), puisque dans un échantillon normal, il est très peu probable que de tels écarts arrivent au hasard. Lorsque les seuils proposés sont dépassés, on peut penser que le modèle ne représente pas bien les données.
À noter qu’il est possible d’enregistrer les valeurs résiduelles et les résiduels standardisés dans des nouvelles variables dans la base de données dans les options disponibles dans SPSS.
On peut également enregistrer la distance de Cook qui nous indiquera l’influence de chaque observation sur le modèle total. Si la distance pour une observation est de plus de 1, elle influence probablement l’estimation des coefficients beta du modèle (Cook et Weisberg, 1982). Pour connaître son influence exacte, il faut refaire la régression sans cette observation et comparer les coefficients beta obtenus. La statistique DFBeta évalue la différence entre les deux. On utilise généralement la valeur DFBeta standardisée pour voir si la différence est importante. Les valeurs plus grandes que 1 indiquent une influence importante de l’observation sur les paramètres.
Le modèle de régression le plus précis et le mieux ajusté sera évidemment celui sans valeurs extrêmes et sans valeurs qui influencent grandement l’estimation des paramètres.