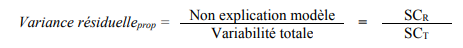RAPPEL THÉORIQUE
Nous avons vu dans la section sur la corrélation comment mesurer la relation entre deux variables continues. Nous allons maintenant voir comment prédire une variable continue à partir d’une autre.
Nous allons également voir comment nous pouvons modéliser cette relation linéaire, c’est-à-dire comment représenter le mieux possible la relation linéaire entre deux variables à l’aide d’une équation mathématique.
Par exemple, si la relation semble rassembler les points autour d’une ligne droite dans le nuage de points, nous pouvons résumer cette relation par l’équation qui résout le mieux cette droite.
De même, il est possible de modéliser mathématiquement d’autres types de relation (quadratique, cubique, exponentielle, etc.).
Les questions auxquelles répond la modélisation de la relation linéaire ressemblent souvent à celles- ci :
- De combien les ventes d’une compagnie peuvent augmenter lorsque le budget de publicité est doublé ?
- De combien le taux de cholestérol augmente-t-il en fonction de l’augmentation du pourcentage de gras ?
- Le nombre d’heures d’étude est-il associé au rendement scolaire ?
Nous allons étudier la plus simple des modélisations: la régression linéaire simple.
Hypothèse nulle
Dans le cas de la régression, l’hypothèse nulle est qu’il n’y a pas de relation entre la variable dépendante et la variable indépendante, donc que la variable indépendante ne permet pas de prédire la variable dépendante.
L’hypothèse alternative est qu’il est possible de prédire la variable dépendante à partir de la variable indépendante.
Prémisses
1. Distribution normale : les valeurs de la variable dépendante sont normalement distribuées.
2. Homogénéité des variances : la variance dans la distribution de la variable dépendante doit être constante pour toutes les valeurs de la variable indépendante.
3. Le prédicteur (la variable indépendante) doit présenter une certaine variance dans les données (pas de variance nulle).
4. Le prédicteur n’est pas corrélé à des variables externes (qui n’ont pas été intégrées au modèle) qui influencent la variable dépendante.
5. Homoscédasticité : pour toutes les valeurs du prédicteur, la variance des résiduels (erreur de mesure) est homogène. Cette prémisse peut être vérifiée par l’examen du nuage de points du croisement entre les valeurs prédites standardisées et les résiduels standardisés. Ce graphique peut être réalisé à partir du bouton Plots de la boite de dialogue principale de la régression.
6. Distribution normale et aléatoire des résiduels : cette prémisse signifie que la différence entre le modèle et les valeurs observées sont près de zéro. Elle peut être vérifiée par l’examen du nuage de points qui a servi à vérifier la prémisse d’homoscédasticité.
7. Les valeurs de la variable dépendante sont indépendantes : chaque valeur de la variable dépendante vient d’une observation distincte. Les observations ne sont pas reliées entre elles.
8. Relation linéaire entre la variable indépendante et la variable dépendante : la relation modélisée est linéaire. Cette prémisse peut être vérifiée par le nuage de points du croisement entre ces deux variables.
Représentation graphique de la relation
Revenons à la relation entre le taux de natalité et l’espérance de vie. Le graphique ci-dessous illustre la relation dont nous parlons, mais pour un échantillon de 15 pays tirés de la base originale.
On remarque que la France a un taux de natalité de 13 par 1 000 habitants et une espérance de vie pour les femmes de 82 ans, tandis que la Mongolie a un taux de natalité de 34 et une espérance de vie de 68 ans.
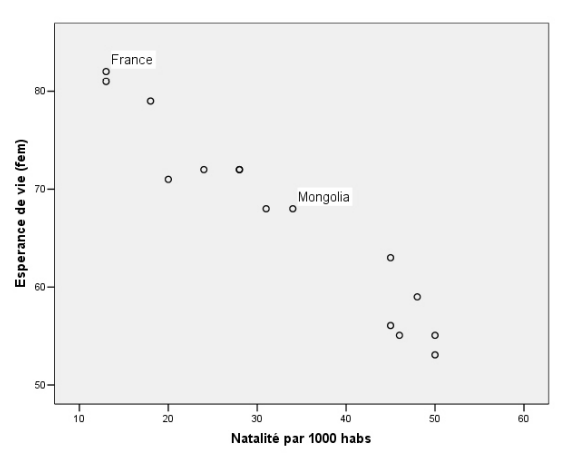
On remarque bien la relation linéaire: les points semblent se concentrer autour d’une ligne imaginaire. Cependant, les points ne tombent jamais exactement sur la ligne droite imaginaire. Sinon, le graphique représenterait une relation parfaite et aurait l’air de ceci:
Le modèle de régression sans prédicteur : la moyenne
Avant de modéliser la relation entre deux variables par la droite de régression, il faut savoir qu’il est possible d’avoir un modèle sans prédicteur.
En fait, le modèle le plus simple pour représenter ou expliquer la variabilité de la variable dépendante (y) est sa propre moyenne. La moyenne d’une variable est en fait sa valeur la plus probable, car toutes les valeurs de l’échantillon tendent vers le centre de la distribution.
Dans le cas qui nous intéresse, le modèle le plus simple pour expliquer ou prédire l’espérance de vie chez les femmes serait d’utiliser la moyenne comme valeur la plus probable de cette variable.
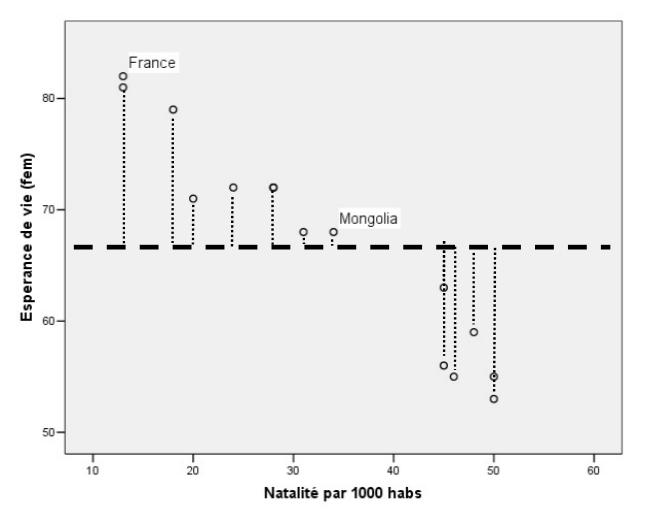
Nous voyons que la moyenne de l’espérance de vie est bel et bien au centre de la distribution et que la moitié des observations se trouvent sous la moyenne et le reste, au-dessus. Le calcul de la qualité d’un modèle sans prédicteur se fait en trouvant la somme des carrés de la différence entre les observations et la moyenne. Ce résultat s’appelle la somme des carrés TOTALE (SCT).
Cependant, il est évident qu’un meilleur modèle que la moyenne doit exister ! En effet, si la moyenne représente très bien les valeurs qui lui sont proches, elle laisse beaucoup d’erreur aux valeurs qui en sont plus éloignées.
Le modèle de régression avec un prédicteur : la variable X
Le but d’un modèle est d’expliquer le mieux possible la variabilité de la variable dépendante (y) à l’aide d’une ou plusieurs variables indépendantes (x). Dans le cas de la régression linéaire simple, le modèle ne contient qu’une seule variable indépendante.
Il est très important de comprendre que pour être valable, un modèle avec prédicteur doit expliquer significativement plus de variance qu’un modèle sans prédicteur ! Sinon, on est encore mieux avec seulement la moyenne. La première chose à faire dans l’interprétation des résultats sera donc de vérifier si le modèle de régression avec prédicteur (notre variable x) sera significativement plus intéressant qu’un modèle sans prédicteur (la moyenne de y).
Dans un premier temps, nous pouvons avoir une idée visuelle du modèle avec prédicteur. En effet, le modèle de régression linéaire est représenté graphiquement par la droite de régression qu’il est possible de tracer entre les points du graphique. Bien que plusieurs droites puissent être tracées, une seule représente bien le modèle.
Aspect graphique du modèle de régression : Estimation de la meilleure droite
Si tous les points tombaient directement sur la droite tracée, il n’y aurait aucun secret pour trouver la meilleure estimation de la droite: nous n’aurions qu’à relier les points entre eux. Par contre, la plupart du temps, les points ne tombent jamais directement sur la droite… et ça devient un peu plus complexe de trouver la meilleure droite.
Allons-y en suggérant trois droites pouvant représenter le mieux la relation linéaire entre ces deux variables…
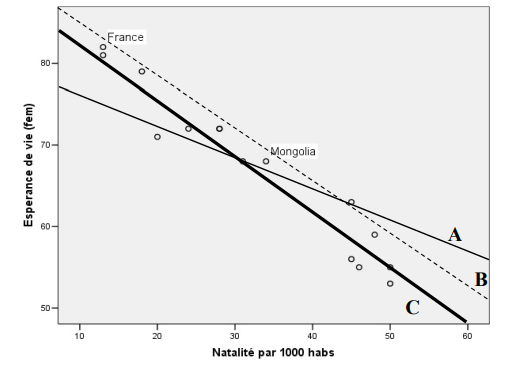
La droite A possède environ le même nombre de points sous et au-dessus de la ligne, mais laisse beaucoup trop de distance non nécessaire entre les points et la droite.
La droite B est plus dans l’axe de la relation que la droite précédente, mais elle est trop au-dessus des points, ce qui laisse encore trop de distance entre la droite et les points du graphique.
La droite C est celle qui colle le mieux à la dispersion des points, c’est celle qui passe le plus près de tous les points du nuage.
La droite des moindres carrés
La droite C n’est pas n’importe quelle droite dessinée au hasard: elle est unique. C’est la droite de régression des moindres carrés.
Ceci signifie que parmi toutes les droites possibles sur ce graphique, la droite C possède la plus petite somme de toutes les distances verticales au carré entre les points et la droite. Regardons le prochain graphique pour comprendre ce qu’il en retourne:
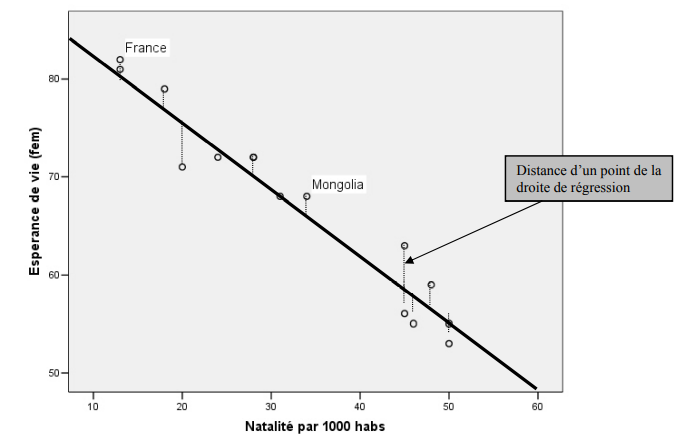
Pour chaque point du graphique, il est possible de calculer la distance verticale qui le sépare de la droite de régression.
En mettant au carré chacune de ces distances et en les additionnant toutes, on arrive à la somme des distances au carré entre les points et la droite de régression. Cette somme s’appelle somme des carrés RÉSIDUELS (SCR).
La droite de régression des moindres carrés (least-square regression line) est la ligne offrant la plus petite somme des distances au carré. Toute autre droite aura une somme des carrés plus élevée.
Aspect algébrique du modèle de régression: Équation de la droite de régression linéaire simple
Le modèle de régression peut aussi se représenter sous une forme mathématique. En fait, la droite de régression s’exprime avec l’équation algébrique décrivant une droite dans un plan cartésien. Si y est la variable placée sur l’axe vertical (ordonnée) et x, la variable placée sur l’axe horizontal (abscisse), l’équation est :
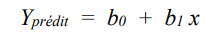
Le coefficient b0 est appelée l’ordonnée à l’origine (intercept ou constante). C’est la valeur prédite de y quand x = 0.
Le coefficient b1 est appelé la pente. C’est le changement sur y lorsque x change d’une unité.
Y est généralement appelé variable dépendante (dans la mesure où nous tentons d’expliquer la variabilité de y avec les valeurs de la variable x) et x est généralement appelé variable indépendante.
Dans notre exemple, la variable dépendante est l’espérance de vie des femmes et la variable indépendante est le taux de natalité. Nous tentons donc d’expliquer la variabilité de l’espérance de vie entre les pays en fonction du taux de natalité.
Si nous remplaçons les termes de l’équation de la droite par les variables de notre graphique :
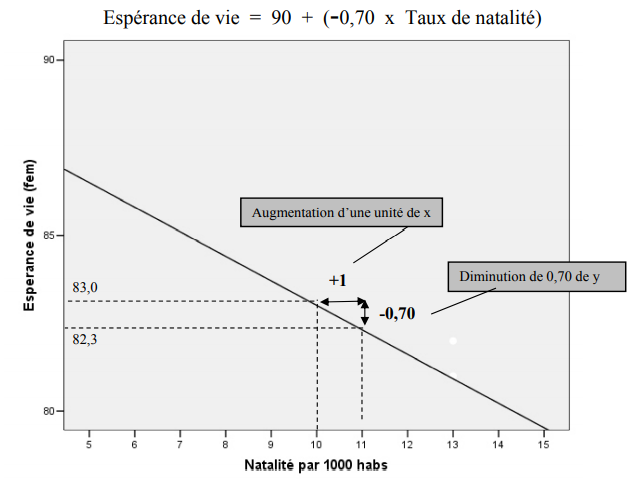
Ce graphique est un agrandissement (un détail) de notre graphique de départ, soit la section entre 5 et 15 naissances par 1 000 habitants et entre 80 et 90 ans d’espérance de vie. Ceci nous permet de mieux saisir visuellement la notion de pente.
L’équation ci-haut nous indique que la pente (b1) est égale à – 0,70. Ceci veut dire que pour chaque augmentation de 1 du taux de natalité (x), il y a une diminution de 0,70 ans de l’espérance de vie chez les femmes. Le graphique nous montre cela clairement. Avec l’augmentation d’une unité de x (natalité) de 10 à 11, on voit bien que l’espérance de vie passe de 83 à 82,3 ans soit une diminution de 0,70 ans, ce qui est bel et bien la valeur de la pente. Gardez à l’esprit que la droite représente les valeurs prédites de y par le modèle de régression.
Si la pente est positive, vous saurez que lorsque la variable indépendante augmente, la variable dépendante en fera autant (et inversement). Plus la valeur de la pente est grande, plus la droite est abrupte (et inversement), ce qui indique qu’un petit changement dans la variable indépendante (x) induit un grand changement dans la variable dépendante (y).
Si la pente est nulle (0), ceci veut dire que le changement de x n’a aucun effet sur y. Il n’y a donc aucune relation linéaire entre ces deux variables.
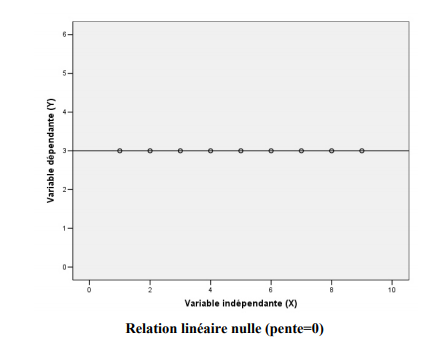
Revenons à notre équation. Après l’interprétation de la pente, il faut faire attention à l’interprétation de l’ordonnée à l’origine. On doit l’interpréter seulement dans les situations où la valeur x = 0 fait du sens. Ici, ce n’est pas le cas. En effet, x = 0 représenterait un pays qui a un taux de natalité nul. Comme ceci est impossible, l’ordonnée à l’origine n’est pas une donnée intéressante et sert uniquement de point de repère pour tracer la droite adéquatement.
Étape 1 : Évaluer la qualité d’ajustement du modèle de régression avec prédicteur : R2 et R
Nous venons de voir l’amélioration de l’explication de la variabilité de l’espérance de vie en partant du modèle le plus simple (seulement la moyenne) jusqu’à l’ajout de la variable indépendante, qui nous a permis de réduire de beaucoup les résiduels entre la droite et les observations.
Il est important de comprendre que cette amélioration du modèle est exactement ce qui est calculé en premier lieu par SPSS et ce qui est convoité par le chercheur ! Est-ce que la variable que je mets en relation avec la variable dépendante permet de mieux expliquer sa variabilité, donc de diminuer de manière significative les résiduels calculés dans un modèle sans prédicteur ? Ce graphique nous aidera à comprendre la stratégie du calcul de cette amélioration.
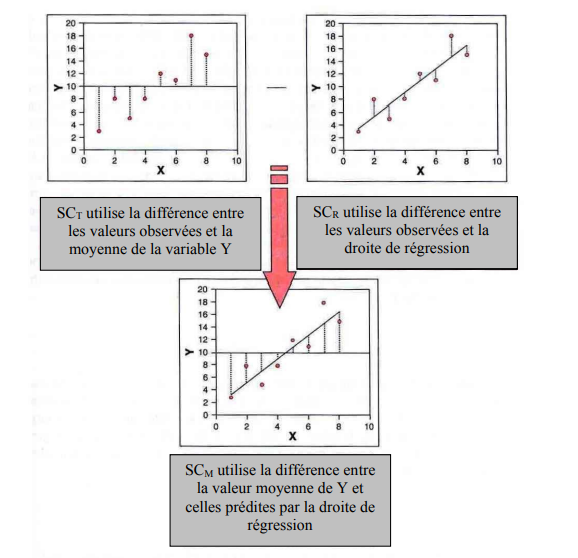
La nouvelle somme des carrés en bas de la figure est cette amélioration due à l’ajout d’une variable indépendante.
Elle représente la différence entre le modèle sans prédicteur et celui avec un prédicteur et s’appelle somme des carrés du MODÈLE (SCM). C’est en fait la soustraction entre SCT (variation totale) et SCR (résiduel).
Lorsque cette somme est très différente de la somme totale, l’ajout de la variable a grandement amélioré le modèle. Une somme plus modeste indiquerait que l’ajout de cette variable indépendante n’a pas permis de mieux expliquer la variabilité de y.
La manière de représenter cette amélioration est de faire le rapport entre la somme des carrés du modèle avec prédicteur (SCM) et la somme des carrés du modèle sans prédicteur (SCT).
Le résultat de ce rapport est appelé R2 et sert à exprimer en pourcentage (lorsque multiplié par 100) la proportion de variance de y qui est expliquée par le modèle (SCM) par rapport à la quantité de variance qu’il y avait à expliquer au départ (SCT).
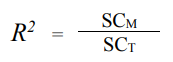
Nous verrons plus loin que la racine carrée de R2 dans le cadre de la régression simple donne le coefficient de corrélation (R) et que celui-ci est un bon estimateur du degré global d’ajustement du modèle.
La valeur F
Les types de somme des carrés servent aussi à calculer l’ajustement du modèle avec le test de la valeur F.
La régression est basée sur le rapport entre le carré moyen de l’amélioration due au modèle (SCM) et le carré moyen de la différence observée entre le modèle et les données réelles (SCR).
Pour le carré moyen du modèle (CMM), on divise le SCM par le nombre de variable dans le modèle (ici 1) et pour le carré moyen résiduel (CMR), on divise la SCR par le nombre de sujets moins le nombre de paramètres « b » estimés (ici b0 et b1).
Au final, il faut comprendre que la valeur F est une mesure de combien le modèle s’est amélioré dans la prédiction de y comparativement au degré d’imprécision du modèle.
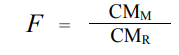
Si un modèle est bon, l’amélioration de la prédiction due au modèle devrait être grande (CMM sera élevé) et les différences entre le modèle (droite de régression) et les valeurs observées, petites (CMR devrait être faible).
Dans un bon modèle, la valeur de F devrait être minimalement plus grande que 1, mais la magnitude exacte du rapport F se calcule avec les tables des valeurs critiques de F, tout comme nous l’avons fait précédemment avec l’ANOVA.
Étape 2 : Évaluation de l’ajustement de la droite de régression aux données
La droite de régression des moindres carrés est la ligne qui résume le mieux les données dans le sens où elle possède la plus petite somme des carrés des résiduels. Ceci dit, cela ne signifie pas nécessairement que cette droite est bien ajustée aux données. Donc, avant d’utiliser la droite de régression pour prédire ou décrire la relation entre deux variables, on doit donc vérifier la qualité d’ajustement de la droite avec les données avec la valeur de R, soit le coefficient de corrélation. Si la droite est peu ajustée aux données, les conclusions basées sur celle-ci seront imprécises voire invalides.
La pente (b1) ne nous donne pas déjà cette information ?
Non. La valeur de la pente ne dépend pas seulement de la force de la relation entre deux variables, mais aussi des unités de mesure des variables. Si on veut prédire le revenu en dollars avec le nombre d’années de scolarité, la pente sera (on le souhaite) très importante. Nous avons besoin d’une autre mesure pour vérifier l’ajustement de la droite.
Le coefficient de corrélation
Nous cherchons donc une mesure absolue qui ne dépend pas des échelles de mesure des variables et qui est facilement interprétable. La statistique la plus utilisée pour ce travail est le coefficient de corrélation de Pearson (R dans les tableaux SPSS de régression ou r dans les textes). Nous avons vu précédemment que R est tout simplement la racine carrée de R2. Cette valeur se trouve dans un des tableaux de résultats de la régression simple.
Pour illustrer notre propos, examinons maintenant les prochains graphiques. Ceux-ci présentent deux modèles de régression qui possèdent les mêmes pentes (b1) et les mêmes ordonnées à l’origine (b0). Pourtant, on voit clairement que ces deux droites sont ajustées différemment aux données. Dans le graphique A, les points sont agglomérés très près de la droite, tandis que dans le graphique B, ils sont beaucoup plus dispersés autour de la droite.
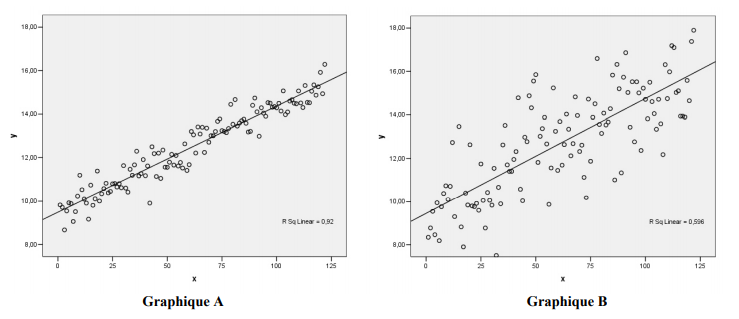
Le coefficient de corrélation pour la relation linéaire du graphique A est de 0,96 tandis que le coefficient de corrélation du graphique B est de 0,77. Comme le premier coefficient est plus élevé (en valeur absolue) que le second, nous pouvons affirmer sans même regarder le graphique que les points du graphique A sont agglomérés beaucoup plus près de la droite que ceux du graphique B.
R = 0 et relation non linéaire
Un coefficient de corrélation de 0 (ou très près de 0) signifie qu’il n’y a pas de relation linéaire entre les deux variables. Cependant, ceci ne veut pas dire qu’il n’existe pas de relation entre les deux variables. Cette relation peut peut-être se modéliser autrement.
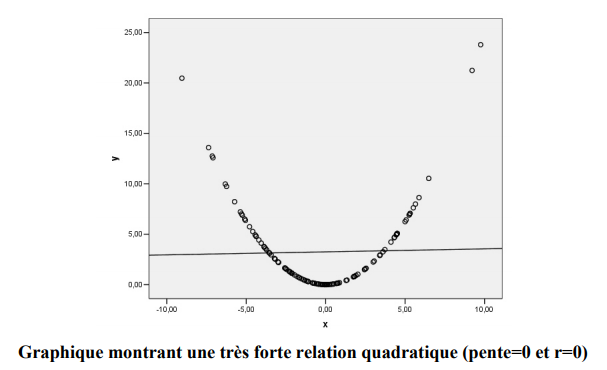
En effet, le graphique ci-haut représente bien une absence de relation linéaire (r = 0), mais aussi une très forte relation quadratique entre les deux variables. C’est donc dire qu’il faut toujours représenter graphiquement les relations entre les variables continues pour s’assurer que le coefficient de corrélation et la droite de régression sont les outils adéquats pour représenter la relation entre deux variables continues.
Qu’est-ce que ça veut dire ?
Lorsque nous prenons l’exemple de la relation entre l’espérance de vie et le taux de natalité, nous savons que les pays n’ont pas tous la même espérance de vie. Il y a une variabilité substantielle de cette variable dans l’échantillon représentée par la somme des carrés totale (SCT). S’il existait une relation parfaite entre cette variable et le taux de natalité, on pourrait attribuer toutes les différences entre les pays au taux de natalité. En d’autres termes, un modèle de régression construit avec le taux de natalité comme variable indépendante expliquerait toutes les différences (variation ou variabilité) observées au plan de l’espérance de vie des femmes.
Dans le cas d’une relation linéaire parfaite, le coefficient de corrélation et son carré (R2) seraient tous deux de 1. Quand tous les points ne tombent pas parfaitement sur la droite, il est possible de calculer la proportion de la variabilité de la variable dépendante expliquée par le modèle de régression. Autrement dit, il n’y aurait pas de différence entre la somme des carrés totale (SCT) et la somme des carrés du modèle (SCM). Par conséquent, le rapport entre les deux donnerait « 1 » ! Le modèle expliquerait parfaitement chaque valeur y sans résiduel.
Étape 3 : Estimation de la variabilité expliquée par le modèle
En dernier lieu, il faut évaluer la proportion de la variabilité totale qui est expliquée par le modèle de régression. Pour ce faire, on utilise les valeurs des sommes des carrés rapportées par SPSS.
En fait, la modélisation par régression tient en trois éléments interreliés qui se trouvent invariablement dans tous les modèles de régression simple ou multiple :
La variabilité totale (SCT) : C’est la variance de la variable dépendante que nous cherchons à expliquer (sans aucun prédicteur). SPSS rapporte cette valeur dans le tableau ANOVA sur la ligne « Total ».
La variabilité expliquée par le modèle (SCM) : C’est la partie de la variance totale qui est expliquée par l’ajout d’un prédicteur, c’est-à-dire la construction d’un modèle. SPSS rapporte cette valeur dans le tableau ANOVA sur la ligne « Régression ».
La variabilité non expliquée par le modèle (SCR) : C’est la partie de la variance qui n’est pas expliquée par le modèle et qui reste donc à expliquer avec d’autres variables indépendantes. SPSS rapporte cette valeur dans le tableau ANOVA sur la ligne « Résidu ».
De ces éléments, on tire deux informations fondamentales en régression, soit :
1) La proportion de variance expliquée par le modèle

Plus la proportion est élevée, plus le modèle est puissant. L’inverse est aussi vrai.
2) La proportion de variance non expliquée par le modèle (variance résiduelle)