RAPPEL THÉORIQUE
Cette section traite de la question suivante : Comment peut-on tester l’hypothèse nulle de l’absence de relation linéaire entre deux variables continues ?
Le test de corrélation (contrairement à la régression simple) ne propose pas d’identifier une variable dépendante et une variable indépendante. On ne cherche qu’à déterminer l’absence ou la présence d’une relation linéaire significative entre les variables.
Par exemple, nous pouvons être intéressé à savoir si le nombre d’heures d’étude est associé au rendement scolaire.
Ces variables peuvent être
associées positivement (r > 0) : plus le nombre d’heures d’étude augmente, plus le rendement augmente;
associées négativement (r < 0 ) : plus le nombre d’heures d’étude augmente, plus le rendement diminue;
non associées (r = 0) : le nombre d’heures d’études n’a aucune influence sur le rendement.
La corrélation est une quantification de la relation linéaire entre des variables continues. Le calcul du coefficient de corrélation de Pearson repose sur le calcul de la covariance entre deux variables continues. Le coefficient de corrélation est en fait la standardisation de la covariance. Cette standardisation permet d’obtenir une valeur qui variera toujours entre -1 et +1, peu importe l’échelle de mesure des variables mises en relation.
Hypothèse nulle
L’hypothèse nulle est donc que les deux variables ne sont pas associées, qu’il n’y a pas de relation entre ces dernières (r = 0).
L’hypothèse alternative est qu’il existe une relation linéaire entre les deux variables.
Prémisse de la corrélation
Chaque paire de variables bivarie normalement.
Retour sur la covariance
Pour bien comprendre le calcul du coefficient de corrélation, il est nécessaire de revenir sur le concept de covariance. Nous avons vu dans le module sur l’ANCOVA que la covariance est une mesure de l’association ou de la relation entre deux variables.
Quand des variables covarient, un écart à la moyenne d’une variable est accompagné par un écart dans le même sens ou dans le sens opposé de l’autre pour le même sujet. Donc, pour chaque valeur qui s’écarte de la moyenne, on s’attend à trouver un écart à la moyenne pour l’autre variable.
Si nous revenons à l’exemple sur le nombre de Coke bus, nous nous rappelons que la variation de la variable du nombre de Coke bus est accompagnée d’une variation dans le même sens pour la variable du nombre de publicités vues.

Comment calculer cette relation ? Il suffit simplement de modifier légèrement la formule de la variance que nous connaissons déjà…
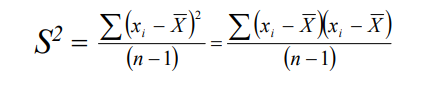
Plutôt que de mettre la différence entre chaque observation et la moyenne au carré, nous multiplions la différence entre chaque observation de la variable x et sa moyenne par la différence entre chaque observation de la variable y et sa moyenne.
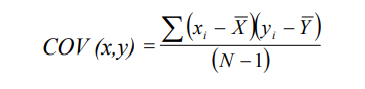
Une covariance positive indique que lorsque la valeur de la variable x augmente, la valeur de la variable y en fait de même, alors qu’une covariance négative indique que lorsque la valeur de la variable x augmente, la valeur de la variable y diminue.
Le problème avec cette formule est que la covariance dépend de l’échelle de mesure. Plus les valeurs d’une des variables sont élevées, plus la covariance sera importante. En ce sens, il est impossible de dire objectivement si la covariance entre les deux variables est large ou relativement faible à moins que l’échelle de mesure soit la même pour les deux variables mises en relation.
Standardisation et coefficient de corrélation
Pour remédier à la situation, M Pearson a eu la brillante idée de faire en sorte que toutes les données soient comparées à partir d’une unité de mesure en laquelle toutes les échelles de mesures peuvent être converties : l’écart-type.
Nous nous rappelons que l’écart-type, comme la variance, est une mesure de la dispersion des données autour de la moyenne. Lorsque nous divisons n’importe quelle distance de la moyenne par l’écart-type, nous obtenons cette distance en unités d’écart-type.
Nous pouvons donc suivre la même logique pour trouver la covariance en unités d’écart-type.
Il faut toutefois se rappeler que puisque nous avons deux variables, nous avons aussi deux écart- types.
Puisque nous avons calculé la variance pour chaque variable avant de les multiplier, nous allons en faire de même avec les écart-types : nous les multiplions et divisons la sommation de la multiplication des deux variances par le produit des deux écart-types.
Nous obtenons ainsi le coefficient de corrélation de Pearson
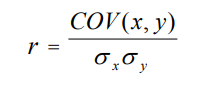
Interprétation du coefficient de corrélation de Pearson
Pour être interprété, le coefficient de corrélation doit être significatif (la valeur de p doit être plus petite que 0,05). Si le coefficient est non significatif, on considère qu’il est semblable à r = 0. Par contre, lorsqu’il est significatif, le coefficient de corrélation donne deux informations importantes :
Le sens de la relation linéaire entre les deux variables : Le coefficient de corrélation, qui présente finalement la covariance standardisée, varie entre – 1 et 1. Un coefficient de 1 indique une corrélation positive parfaite entre les deux variables. À l’inverse, un coefficient de – 1 indique une corrélation négative parfaite: lorsque la variable x augmente, la variable y diminue dans la même proportion. Dans les deux cas, les points tombent parfaitement sur la droite. Un coefficient de 0 indique qu’il n’y a aucune relation entre les deux variables. Ainsi, la variation de l’une n’est aucunement associée à la variation de l’autre.
La force de la relation linéaire entre les deux variables : Plus la valeur du coefficient est proche de + 1 ou de – 1, plus les deux variables sont associées fortement. Au contraire, plus le coefficient est près de 0, moins les variables partagent de covariance et donc, moins l’association est forte. On peut qualifier la force de cette relation avec les balises de Cohen concernant la taille d’effet.
Calcul du degré de signification
Pour déterminer la valeur de p associée au coefficient de corrélation, on calcule une valeur de t à l’aide de la formule suivante. Cette valeur de t est par la suite associée à une valeur de p en fonction du degré de liberté, tout comme pour le test t. SPSS ne présente que la valeur de p.
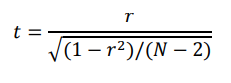
La taille d’effet
Pour la corrélation, nous n’avons pas à effectuer de calcul particulier pour connaître la taille d’effet. Nous regardons seulement la valeur du coefficient et nous l’interprétons selon les balises de Cohen (1988) :
