RAPPEL THÉORIQUE
Le test t pour échantillon unique est utilisé pour tester si la moyenne d’un échantillon (x) pour une variable spécifique est « probable » ou « improbable » en regard de l’hypothèse que cette moyenne provient d’un échantillon qui a été tiré au hasard d’une population dont nous connaissons la moyenne (μ), mais non l’écart-type. Dans ce cas, la distribution échantillonnale des moyennes ne suit plus la forme de la distribution normale. En fait, lorsque nous ne connaissons pas tous les paramètres de la population (moyenne et écart-type réel), nous pouvons utiliser la distribution t, apparentée à la distribution normale, et tester si un échantillon provient d’une population avec une moyenne connue, mais un écart-type qui ne l’est pas.
L’hypothèse nulle qui est testée dans cette situation d’analyse est la suivante :
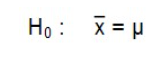
Dans le cas du rejet de H0, l’hypothèse alternative (hypothèse de recherche) est la suivante :
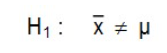
Le test t pour une seule moyenne teste la probabilité d’erreur (valeur de p ou degré de signification) associée au rejet de cette hypothèse nulle si celle-ci est vraie dans la réalité.
La distribution t
On pourrait croire que l’écart-type obtenu avec l’échantillon est un bon estimateur de la vraie valeur populationnelle, mais ce n’est pas le cas, surtout avec un échantillon de petite taille. Tout comme la moyenne, l’écart-type (et la variance) d’un échantillon varie d’un échantillon à l’autre et possède une distribution échantillonnale. Si on prend la valeur de l’écart-type de l’échantillon, on introduit une imprécision.
Rappelez-vous la formule du calcul du score Z pour la distribution normale. Si on insère un écart-type trop grand, le score Z est trop petit (sous-estimé) et si on introduit un écart-type trop petit, le score Z est trop grand (sur-estimé). C’est pourquoi, lorsqu’on ne connaît pas l’écart-type réel d’une population et qu’on l’estime à partir d’un échantillon, la distribution échantillonnale de l’écart-type ne suit plus une distribution normale, mais bien une distribution t. Cette dernière tient compte de l’erreur additionnelle qui s’ajoute en calculant le score Z avec une approximation de l’écart-type populationnel. Cette distribution a une forme similaire à celle de la distribution normale, mais possède des queues avec plus d’espace sous la courbe dans le but de compenser l’imprécision induite par la substitution de l’écart-type de l’échantillon dans le calcul de l’erreur-type.
La figure ci-dessous illustre la différence entre une distribution normale et une distribution t lorsque l’échantillon comprend 15 sujets.

Une autre différence entre la distribution t et la distribution normale, c’est que la forme de la distribution t varie en fonction du nombre d’observations dans l’échantillon. En fait, plus le nombre d’observations est petit, plus les queues de la distribution sont larges. Autrement dit, la distribution s’aplatit et s’étend davantage autour de la grande moyenne. À l’inverse, plus le nombre d’observations augmente, plus les extrémités de la distribution s’amincissent jusqu’à prendre pratiquement la forme de la distribution normale.
Ceci provient du fait que l’estimation de l’écart-type est plus près de la vraie valeur populationnelle avec des échantillons de grande taille. Plus l’échantillon est grand, plus la précision de l’approximation est grande et donc, moins important devient l’écart avec la valeur inconnue de l’écart-type populationnel.
Concrètement, ceci signifie que le seuil critique (toujours fixé à 5 %) de la distribution t va varier en fonction du degré de liberté (n-1). Plus le degré de liberté augmente, plus le seuil critique de 5 % de la distribution se rapprochera de celui de la courbe normale. Au contraire, plus le degré de liberté est petit, plus le seuil critique augmentera. Par exemple, pour un échantillon de n = 15, un seuil critique fixé à 1,96 (comme celui de la distribution normale) équivaut à une probabilité bilatérale de 7,4 %. La correction fixe cette valeur critique de t à 2,15, valeur qui correspond avec une probabilité bilatérale de 5 %. La valeur critique change légèrement avec chaque augmentation du degré de liberté.
Calcul du score t et positionnement d’un cas
Voici un exemple concret d’une situation d’analyse pour laquelle un test t pour une seule moyenne est approprié.
Nous voulons savoir si les gens avec un diplôme collégial ou plus proviennent d’une population en emploi qui travaille en moyenne 40 heures par semaine. Avec la base GSSNET, nous avons calculé le nombre d’heures moyen de travail par semaine. Les diplômés du collégial et de l’université de cette base travaillent en moyenne 45,17 heures par semaine.
Pour répondre à la question de départ, nous devons postuler l’hypothèse nulle associée à cette situation d’analyse. L’hypothèse nulle est à l’effet que l’échantillon (et sa moyenne) provient effectivement d’une population en emploi travaillant en moyenne 40 heures par semaine. En termes statistiques, l’hypothèse nulle serait formulée ainsi :
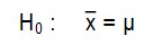
Pour tester cette hypothèse, nous devons positionner l’échantillon par rapport à la distribution échantillonnale de la moyenne. Puisque nous ne connaissons pas l’écart-type de la population, nous allons positionner l’échantillon sur une distribution t.
Comme nous travaillons avec la distribution échantillonnale, nous devons d’abord trouver l’erreur-type de la moyenne (plutôt que l’écart-type). Pour ce faire, nous utilisons la formule suivante :

Nous pouvons maintenant calculer le score t à partir de l’erreur-type que nous venons de trouver:

La forme de la distribution t utilisée pour positionner le score t aura 270 degrés de liberté (n-1). À cause du grand nombre de sujets, elle ressemble beaucoup à la distribution normale. La valeur du score t est élevée (t = 6,02) ce qui positionne l’échantillon au-delà du seuil critique de la distribution (t = 1,98). À cet égard, le degré de signification doit être très près de zéro. En regard du test d’hypothèse, ces résultats indiquent que nous devons rejeter l’hypothèse nulle. Pourquoi ? Parce que les probabilités de se tromper en la rejetant (degré de signification) sont plus faibles que 5 %. L’hypothèse nulle ne semble donc pas être la plus probable. Nous devrons donc l’infirmer à la faveur de l’hypothèse de recherche.
Intervalle de confiance
Très bien. Les travailleurs avec un diplôme collégial semblent former un groupe différent de la population travaillant en moyenne 40 heures par semaine, mais notre échantillon a-t-il la vraie moyenne de ce groupe de travailleurs ? En effet, cet échantillon n’est qu’un échantillon parmi TOUS les échantillons de 271 travailleurs possibles et il est impossible de connaître la moyenne de la distribution échantillonnale.
Cependant, nous avons estimé l’erreur-type de cette distribution échantillonnale en remplaçant l’écart-type populationnel par l’écart-type de l’échantillon dans la formule de l’erreur-type. Ce calcul donne environ 0,86 heures. Si la moyenne échantillonnale est distribuée normalement, nous savons qu’environ 95 % de toutes les moyennes possibles se trouveront entre plus ou moins 2 erreur-types de la vraie moyenne populationnelle, soit entre 45,17 – (0,86 x 2) heures et 45,17 + (0,86 x 2).
Nous pouvons donc être confiants à 95 % que la vraie moyenne de nos travailleurs se situe entre 43,45 heures et 46,89 heures.
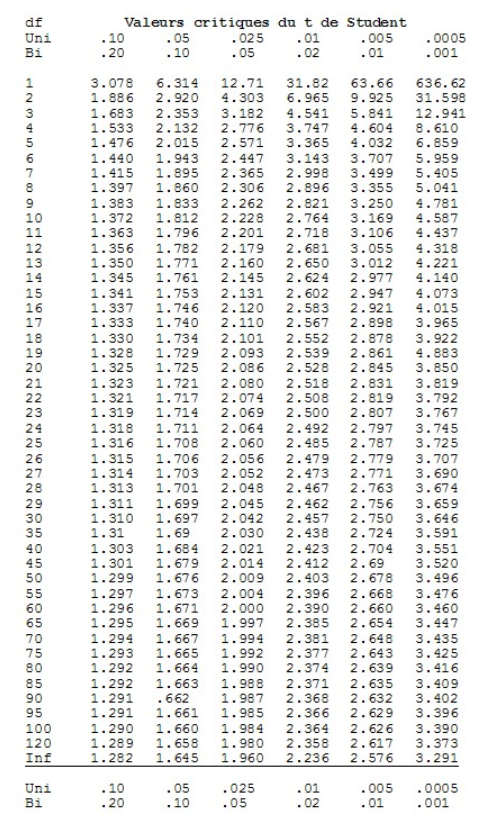
Nous devons toujours nous référer à des tables spécialisées de la distribution de t selon le degré de liberté (n – 1) pour déterminer le seuil de signification qui y est associé. Le tableau suivant présente les principales valeurs critiques de la distribution t de Student. Les premières rangées indiquent les valeurs critiques choisies lorsque le test est unidirectionnel (uni) ou bidirectionnel (bi) et la première colonne, le degré de liberté.