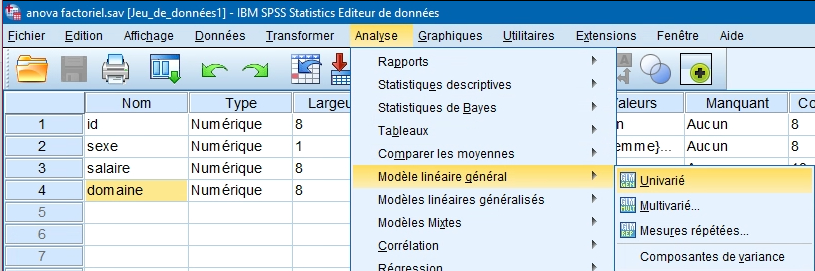
1. L’analyse de variance à plan factoriel se fait à partir de la même boîte que l’ANCOVA. Il faut choisir le Modèle linéaire général – Univarié dans le menu Analyse.
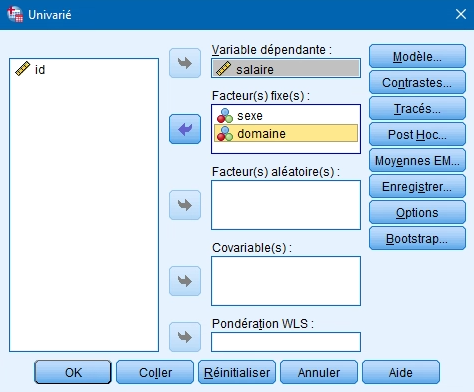
2. Dans la boîte de dialogue principale, insérez la variable dépendante dans la première boîte et les deux variables catégorielles dans la boîte facteur(s) fixe(s).
Le bouton MODÈLE
Vous pouvez laisser l’option par défaut, soit le modèle factoriel complet, qui inclut l’effet de toutes les variables indépendantes et l’effet d’interaction entre ces dernières. Si vous voulez tester un élément plus précis, vous pouvez sélectionner le modèle personnalisé et transférer les variables pour lesquelles vous désirez mesurer l’effet dans la boîte de droite.
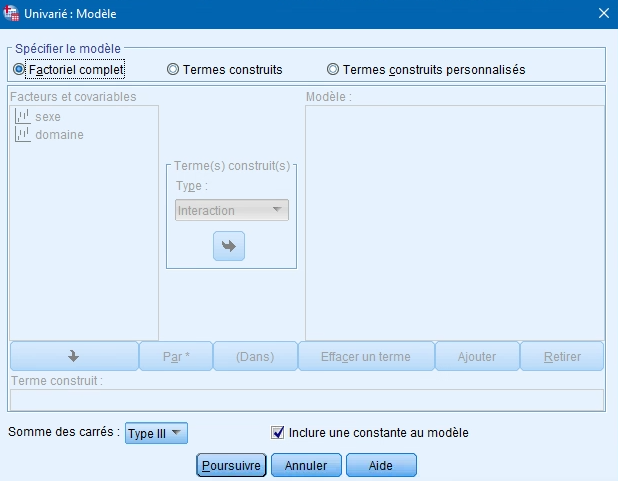
Vous pouvez également choisir le type de somme des carrés qui sera utilisé pour l’analyse. Par défaut, SPSS priorise la somme des carrés de type III qui n’est pas influencée par le nombre de participants dans chaque groupe. Le résultat obtenu sera donc le même que vous ayez des groupes de taille équivalente ou non. Conservez cette option, à moins que vous ayez beaucoup de données manquantes. Dans ce cas, optez pour le type IV.
Bien entendu, vous laissez l’option « Inclure la constante au modèle » cochée.
Pour revenir à la boite de dialogue principale, cliquez sur POURSUIVRE.
Le bouton CONTRASTES
Celui-ci peut être intéressant si vous voulez identifier quels groupes se distinguent pour chaque VI. Par contre, vous ne pourrez pas savoir où se situent les différences pour le terme d’interaction, ce qui est un peu plus embêtant. Les cracks peuvent toutefois se construire une syntaxe et y arriver…
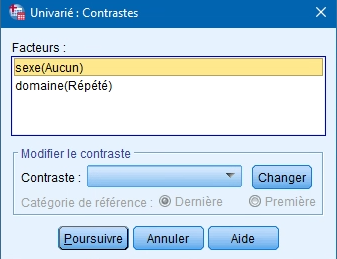
Vous avez le choix entre plusieurs contrastes, dont les plus fréquemment utilisés :
- Simple : compare les groupes (2 et 3) avec le groupe de référence (1). Par exemple, si le groupe soins infirmiers est la référence, le salaire de ces professionnels sera comparé à celui des éducateurs à l’enfance et à celui des techniciens en génie civil.
- Répété : compare les groupes 1 et 2, puis 2 et 3.
- Helmert : compare le groupe 1 avec les groupes suivants, puis les groupes 2 et 3.
- Différencié d’ordre : compare les groupes 1 et 2, puis le groupe 3 aux deux précédents.
Comme notre variable catégorielle est nominale, les deux premiers sont plus pertinents. Il n’y a en effet par d’ordre hiérarchique entre les groupes, donc le fait de les additionner ne nous apporte pas une information intéressante. Nous allons prendre le contraste répété.
N’oubliez pas de cliquer sur POURSUIVRE une fois votre choix effectué avant de revenir à la boite de dialogue principale.
Le bouton TRACÉS
Cette option est vraiment intéressante, car elle vous permet d’observer dans un graphique la relation entre les groupes, donc d’interpréter plus facilement le terme d’interaction. Transférez la première variable catégorielle (DOMAINE) dans la boîte Axe horizontal et la deuxième (SEXE) dans la boîte Courbes distinctes. En fait, l’ordre d’entrée des variables n’a pas tellement d’importance. Vous choisissez ce qui fait plus de sens pour vous.
Cliquez sur POURSUIVRE. L’interaction entre les deux variables devrait apparaître dans la boîte diagrammes. Cliquez ensuite sur POURSUIVRE.
Le bouton POST HOC
Si vous n’avez pas fait de contrastes, vous pouvez effectuer des tests post-hoc. Vous devez d’abord transférer les variables à tester dans la boîte Tests post-hoc.
Le premier encadré offre différents tests à réaliser si la prémisse d’homogénéité des variances est respectée. Il serait fastidieux de décrire l’ensemble de ces tests. Nous n’allons donc que présenter les plus fréquemment utilisés :
- Bonferroni : utilise le test t pour comparer les moyennes des groupes deux à deux et ajuste le degré de signification en divisant 0,05 par le nombre de comparaisons à effectuer, donc il diminue le risque de commettre une erreur de type I. C’est celui que nous privilégions.
- Tukey : compare les groupes deux à deux à partir d’une distribution t standardisée et ajuste le degré de signification pour le risque d’erreur. Il est plus puissant que le test Bonferroni avec des grands échantillons.
- Scheffe : réalise simultanément toutes les comparaisons de moyennes deux à deux à partir de la distribution F. Il peut être utilisé pour examiner toutes les combinaisons linéaires possibles des moyennes de groupe, pas seulement les comparaisons deux à deux. Il est moins puissant que le test Tukey.
Le deuxième encadré offre des tests de comparaisons multiples lorsque la prémisse d’homogénéité des variances n’est pas respectée.
- Tamhane’s T2 : ce test est très conservateur (faible probabilité de commettre une erreur de type I).
- Dunnett’s T3 et C : ces deux tests font une correction sévère pour réduire le risque d’erreur de type I.
- Games-Howell : assure la plus grande puissance statistique, mais le risque de commettre une erreur de type I est plus élevée lorsque l’échantillon est petit. Ce test est aussi précis lorsque les groupes sont inégaux.
Le Niveau de signification : vous pouvez indiquer le seuil de signification que vous voulez. Par défaut, ce seuil est fixé à 0,05, comme pour les autres tests.
Cliquez sur POURSUIVRE.
Le bouton MOYENNE
La première partie fournit la moyenne marginale estimée dans la population pour l’ensemble du modèle (OVERALL), chaque VI ou l’interaction entre 2 VI. Vous devez transférer les variables pour lesquelles vous désirez obtenir ces informations dans la boite de droite. Vous pouvez comparer les effets principaux pour chacune des variables du modèle à partir des moyennes estimées tout en ajustant l’intervalle de confiance (LSD, Bonferroni ou Sidak), mais nous ne nous rendrons pas jusque là.
Le bouton ENREGISTRER
Celui-ci vous permet d’enregistrer certains résultats des analyses comme nouvelles variables dans la base de données. Évidemment, il y aura une valeur par individu. Cette stratégie est principalement utilisée lorsque vous désirez examiner la distribution des valeurs résiduelles.
L’encadré Prévisions permet de calculer les valeurs prédites par le modèle. Ces dernières sont dans l’échelle originale (non standardisés). De plus, pour chaque valeur, vous pouvez obtenir son erreur-type (erreur standard).
L’encadré des Résidus indique, pour chaque individu, la différence entre la valeur prédite et la valeur observée. Vous pouvez obtenir les résidus
- Non standardisés : dans l’échelle originale
- Standardisés : en écart-type, donc sous forme de score Z
- De Student : résiduels non standardisés divisés par un estimé de leur écart-type variant point par point
- Supprimés : différence entre les valeurs prédites ajustées (valeur calculée pour un cas lorsque celui-ci est retiré du modèle) et les valeurs observées.
L’encadré des Diagnostics offre deux tests qui permettent d’identifier les observations qui influencent fortement le modèle :
- Distance de Cook : statistique qui considère l’effet d’un cas sur l’ensemble du modèle. Les valeurs plus élevées que 1 doivent retenir l’attention du chercheur.
- Valeurs influentes : mesure de l’influence de la valeur observée de la variable dépendante sur les valeurs prédites. Cette valeur se calcule par le nombre de prédicteurs (k) + 1 divisé par le nombre de d’observations (N) et se situe entre 0 (aucune influence de l’observation sur la valeur prédite) et 1 (influence complète de l’observation sur la valeur prédite).
Enfin, vous pouvez, grâce à l’encadré Statistiques à coefficients, créer une nouvelle base de données incluant une matrice de variance-covariance des paramètres estimés par le modèle. De plus, pour chaque VD, SPSS créera une rangée des paramètres estimés, une pour la signification de la valeur t associée à chaque paramètre ainsi qu’une pour les degrés de libertés résiduels. Si vous ajouter plus d’une VD, il y aura les mêmes statistiques pour chacune.
Le bouton OPTIONS
Les options disponibles sont les mêmes que pour l’ANCOVA puisque nous partons de la même boîte de dialogue principale.
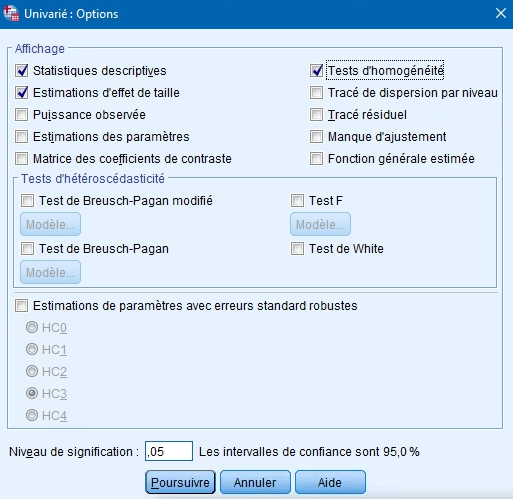
L’encadré Affichage crée un tableau dans la fenêtre de résultats pour chaque item demandé. Nous recommandons de sélectionner minimalement les statistiques descriptives qui vous fourniront la moyenne, l’écart-type et le N pour chaque groupe considéré dans l’analyse. Cela facilitera l’interprétation des effets des deux variables et de l’effet d’interaction. Sélectionnez également le test d’homogénéité des variances afin de déterminer si vous respectez la prémisse d’égalité des variances. Enfin, vous pouvez demander un estimé des tailles d’effets.
Cliquez ensuite sur POURSUIVRE puis OK pour que SPSS réalise l’analyse.